Softeer
연습문제를 담을 Set을 선택해주세요. 취소 확인
softeer.ai
문제는 위 링크에 접속하면 직접 문제를 풀어보실 수 있습니다!
문제 설명
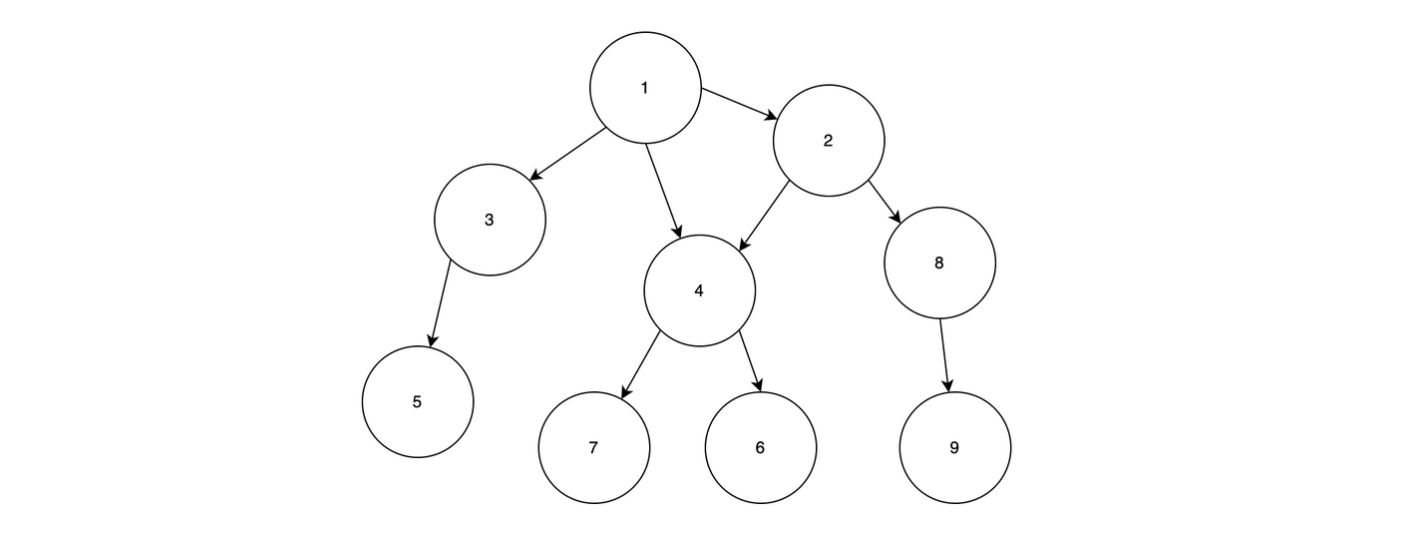
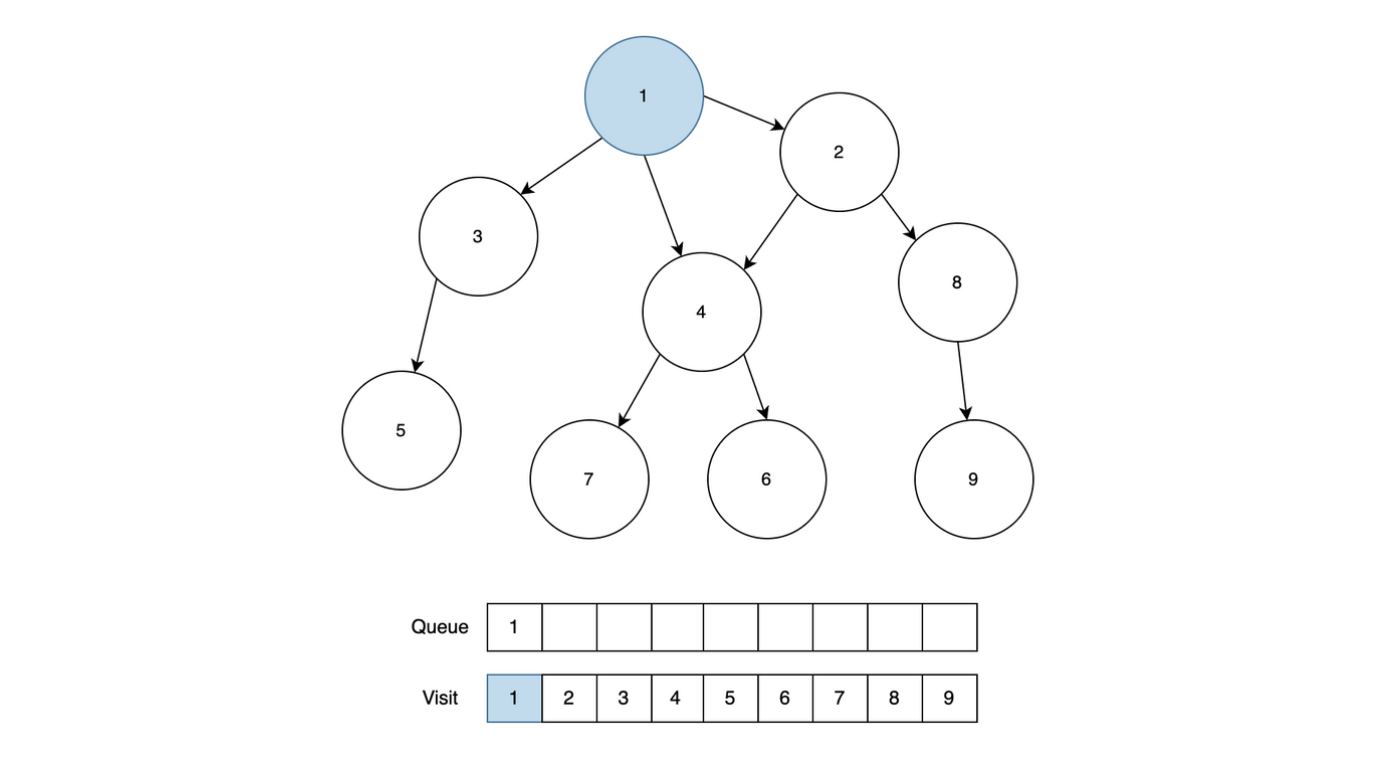
어떤 부서의 업무 조직은 완전이진트리 모양이다. 즉, 부서장이 루트이고 부서장 포함 각 직원은 왼쪽과 오른쪽의 부하 직원을 가진다. 부하 직원이 없는 직원을 말단 직원이라고 부른다.
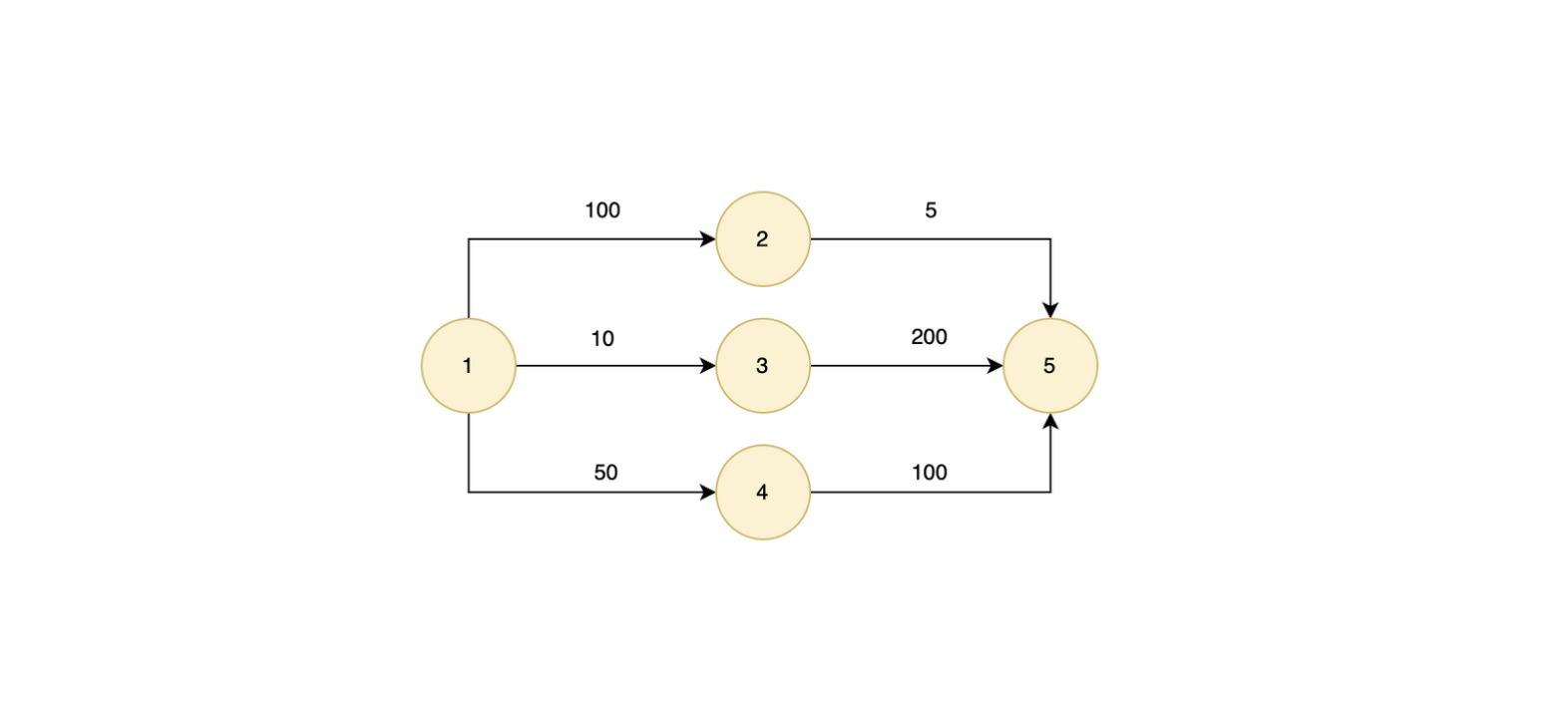
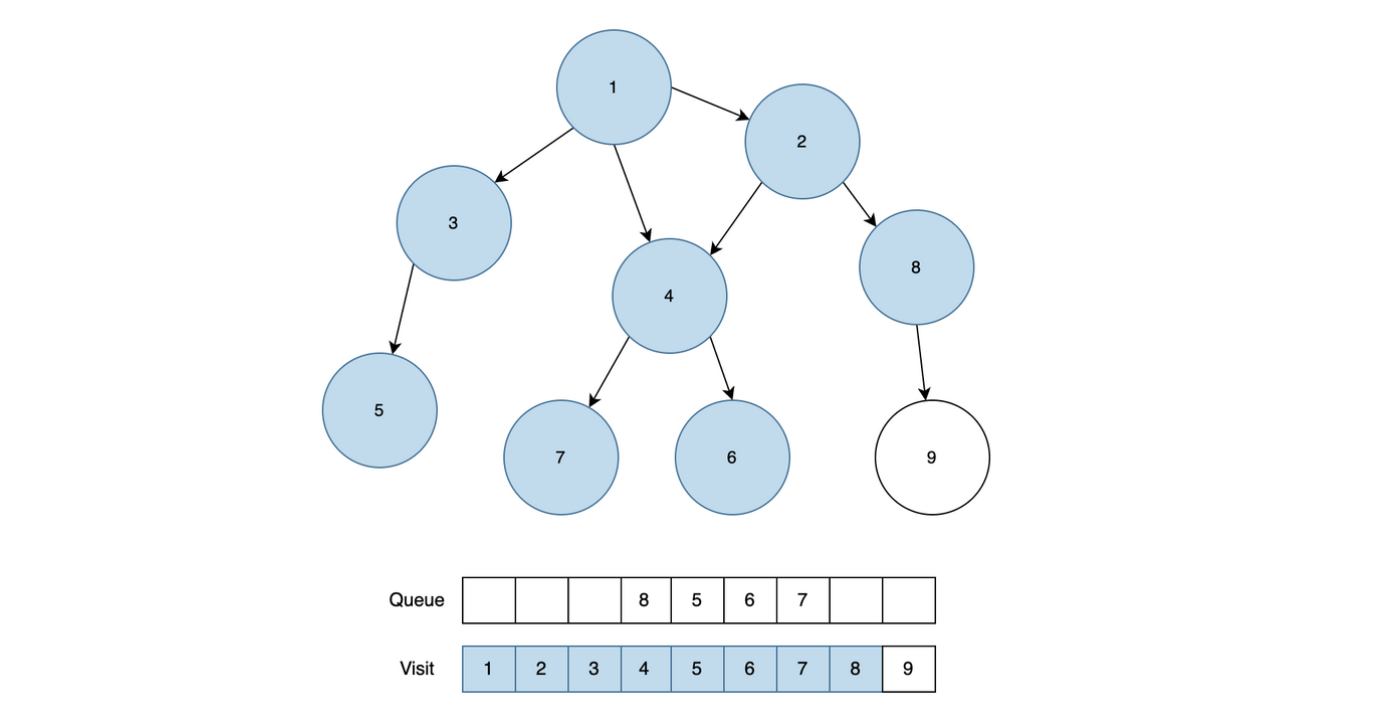
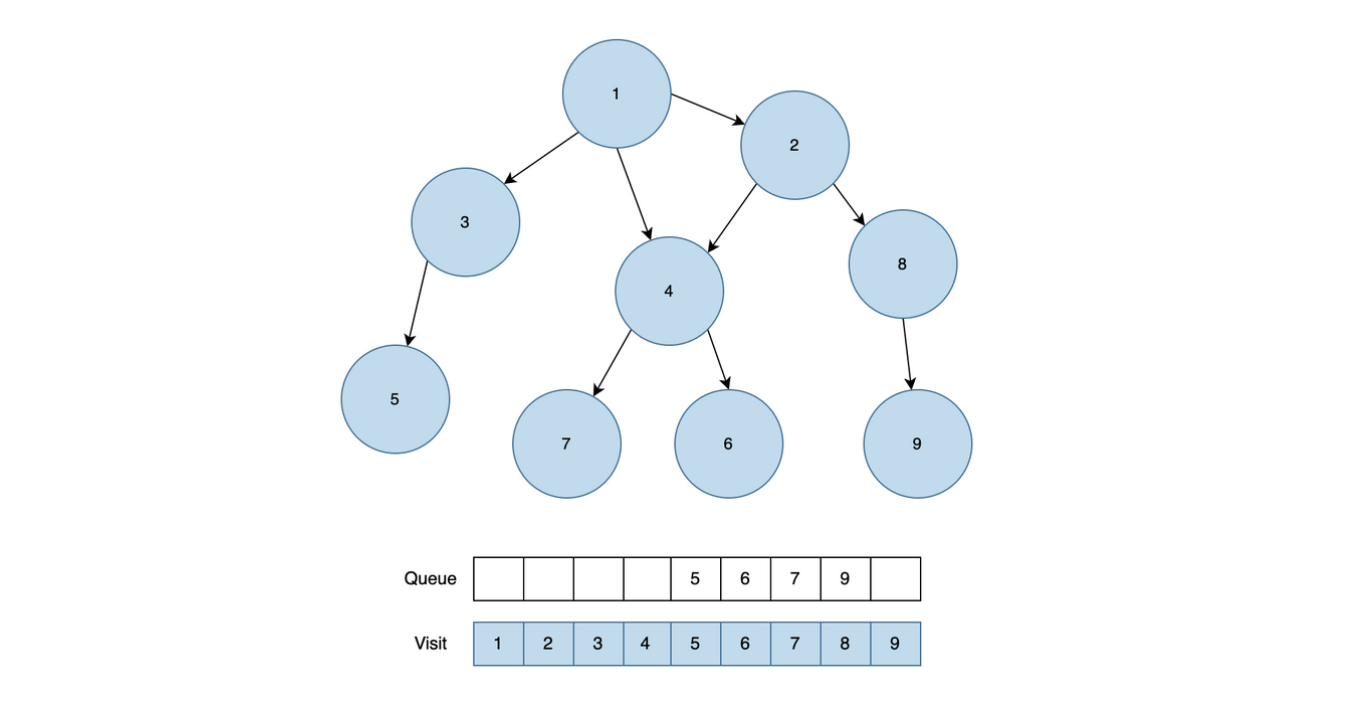
모든 말단 직원은 부서장까지 올라가는 거리가 동일하다. 조직도 트리의 높이는 H이다. 아래는 높이가 1이고 업무가 3개인 조직도를 보여준다.

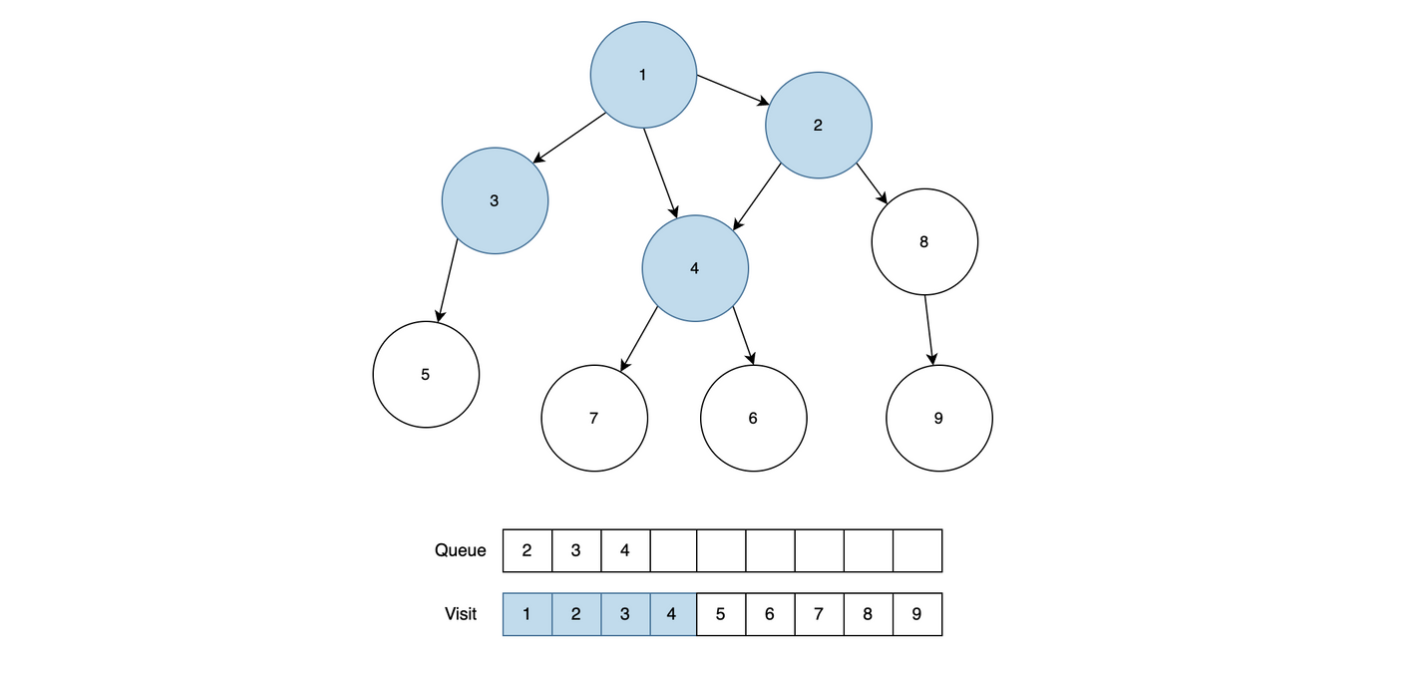
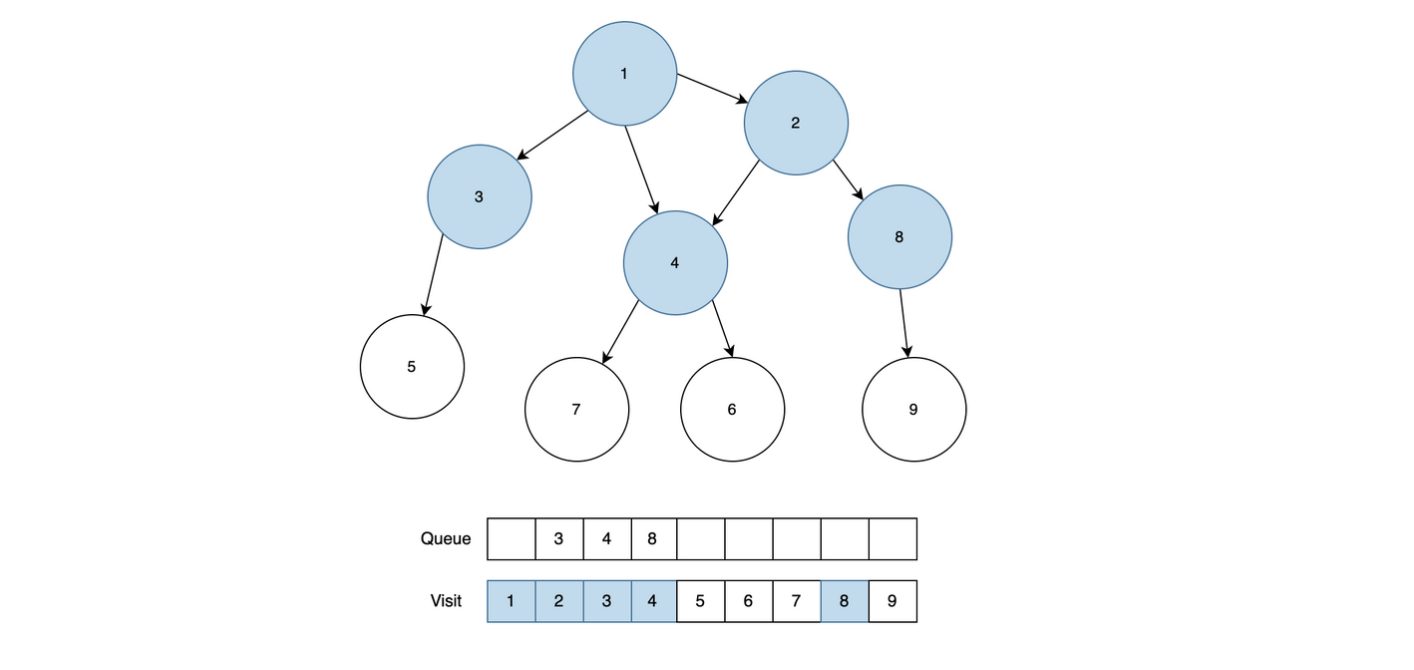
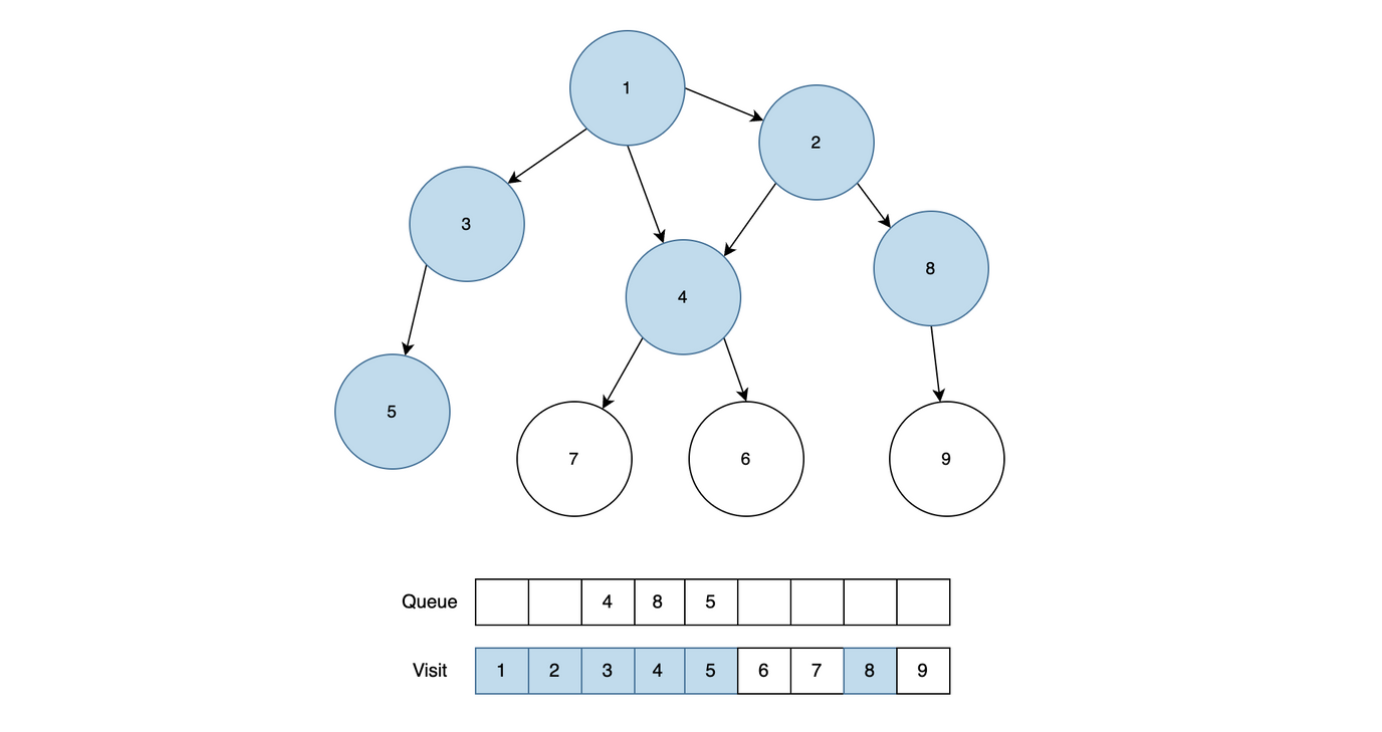
업무는 R일 동안 진행된다. 처음에 말단 직원들만 각각 K개의 순서가 정해진 업무를 가지고 있다. 각 업무는 업무 번호가 있다. 각 날짜에 남은 업무가 있는 경우, 말단 직원은 하나의 업무를 처리해서 상사에게 올린다. 다른 직원들도, 대기하는 업무가 있는 경우 업무를 올라온 순서대로 하나 처리해서 상사에게 올린다. 단, 홀수 번째 날짜에는 왼쪽 부하 직원이 올린 업무를, 짝수 번째 날짜에는 오른쪽 부하 직원이 올린 업무를 처리한다.
부서장이 처리한 일은 완료된 것이다. 업무를 올리는 것은 모두 동시에 진행한다. 따라서 그날 올린 업무를 상사가 처리하는 것은 그 다음날에야 가능하다.
부서의 조직과 대기하는 업무들을 입력 받아 처리가 완료된 업무들의 번호의 합을 계산하는 프로그램을 작성하라.
제약조건
1 ≤ H ≤ 10
1 ≤ K ≤ 10
1 ≤ R ≤ 1,000
입력형식
첫 줄에 조직도의 높이 H, 말단에 대기하는 업무의 개수 K, 업무가 진행되는 날짜 수 R이 주어진다.
그 다음 줄부터 각각의 말단 직원에 대해 대기하는 업무가 순서대로 주어진다.
제일 왼쪽의 말단 직원부터 순서대로 주어진다.
출력형식
완료된 업무들의 번호 합을 정수로 출력한다.
입력예제1
1 1 1
1
2
출력예제1
0
입력예제2
1 3 2
9 3 7
5 11 2
출력예제2
5
👨🏻💻 생각해보기
1. 말단 직원과 상사의 남은 일은 다르게 처리되어야 할 거 같다는 생각을 했다.
- 말단 직원은 그냥 자신에게 남겨져있는 일을 하루에 하나씩 상사에게 올려주기만 하면된다.
- 상사는 왼쪽 직원이 올려준 일, 오른쪽 직원이 올려준 일을 분류해서 처리해야 한다.
- 날짜가 1일이라면 홀수번째(왼쪽) 직원이 준 일을 처리해서 상사에게 올려야한다.
- 날짜가 2일이라면 짝수번째(오른쪽) 직원이 준 일을 처리해서 상사에게 올려야한다.
2. 들어온 일의 순서대로 처리되어야 하고, 말단과 상사를 구분해야 한다?
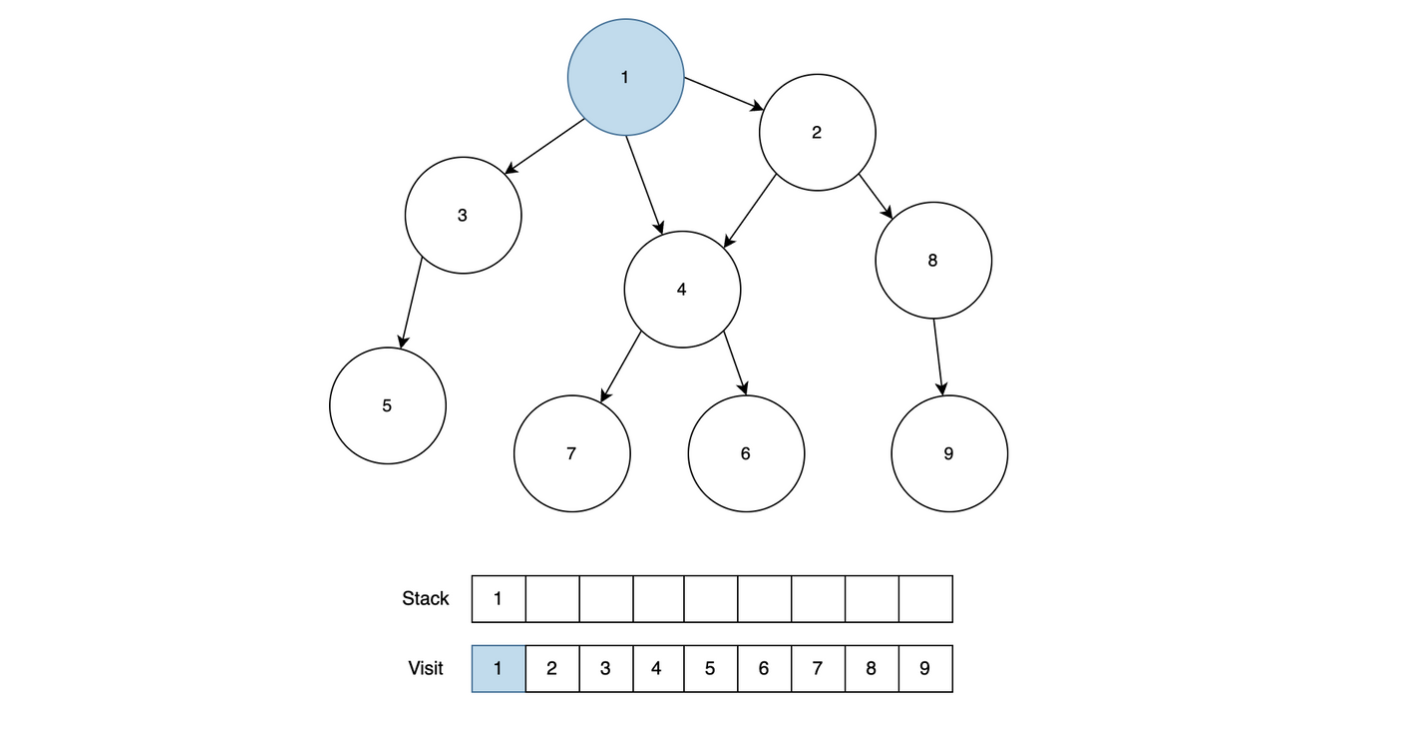
- 들어온 일을 순서대로 처리하기 위해서는 Queue를 사용하기로 했다.
- 직원 객체를 만들어서 사용했고, 생성자에서 말단과 상사를 구분하도록 만들었다.
- 말단이라면 남아있는 일에 대한 Queue를 하나만 만들어준다.
- 누군가의 상사라면 남아있는 일에 대한 Queue를 두 개(왼쪽, 오른쪽) 만들어준다.
3. R(날짜) 만큼 반복을 진행하면서 로직을 수행한다.
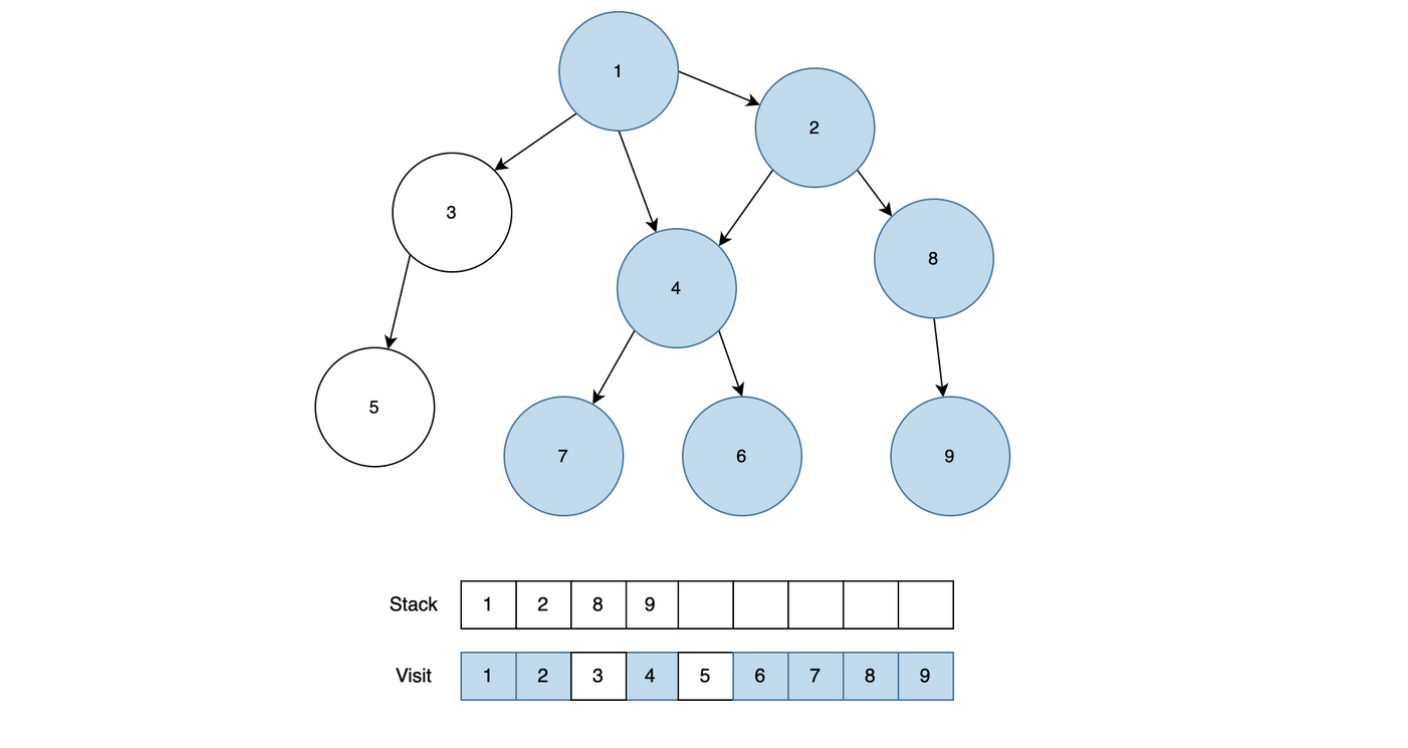
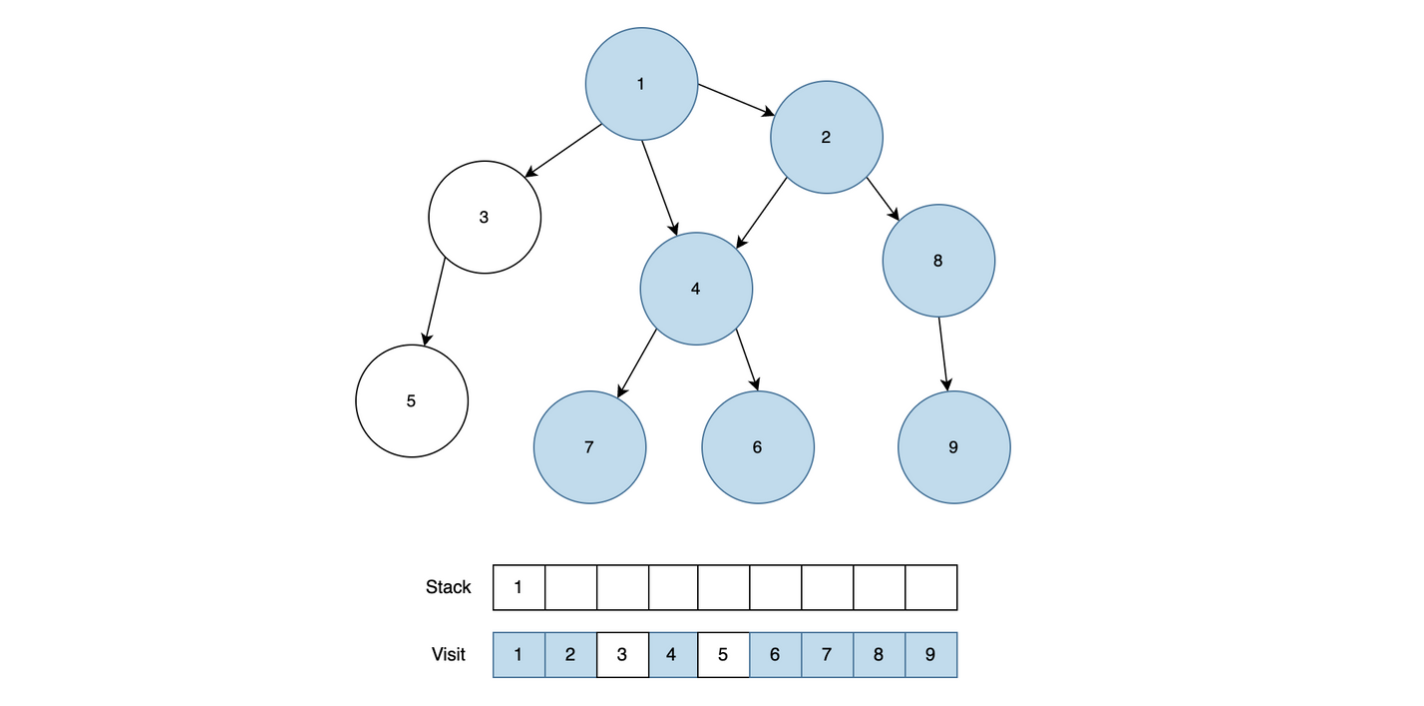
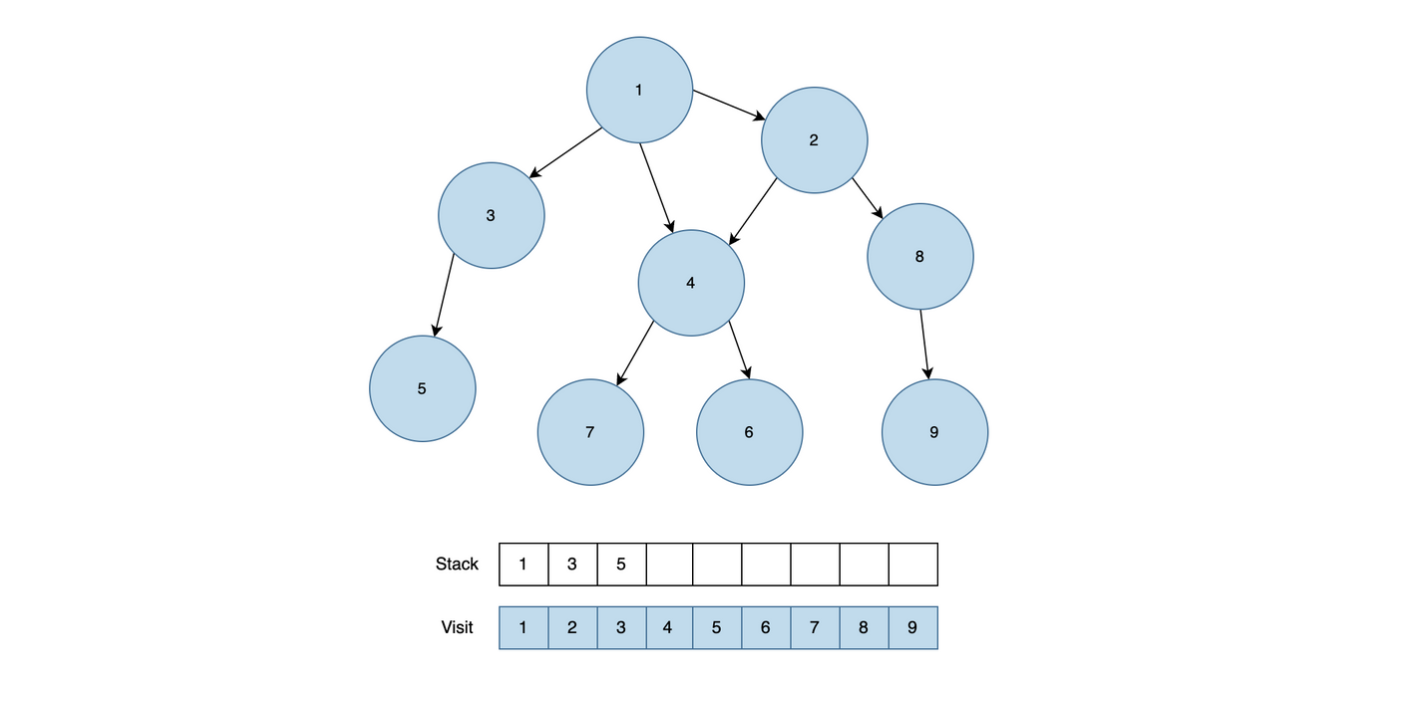
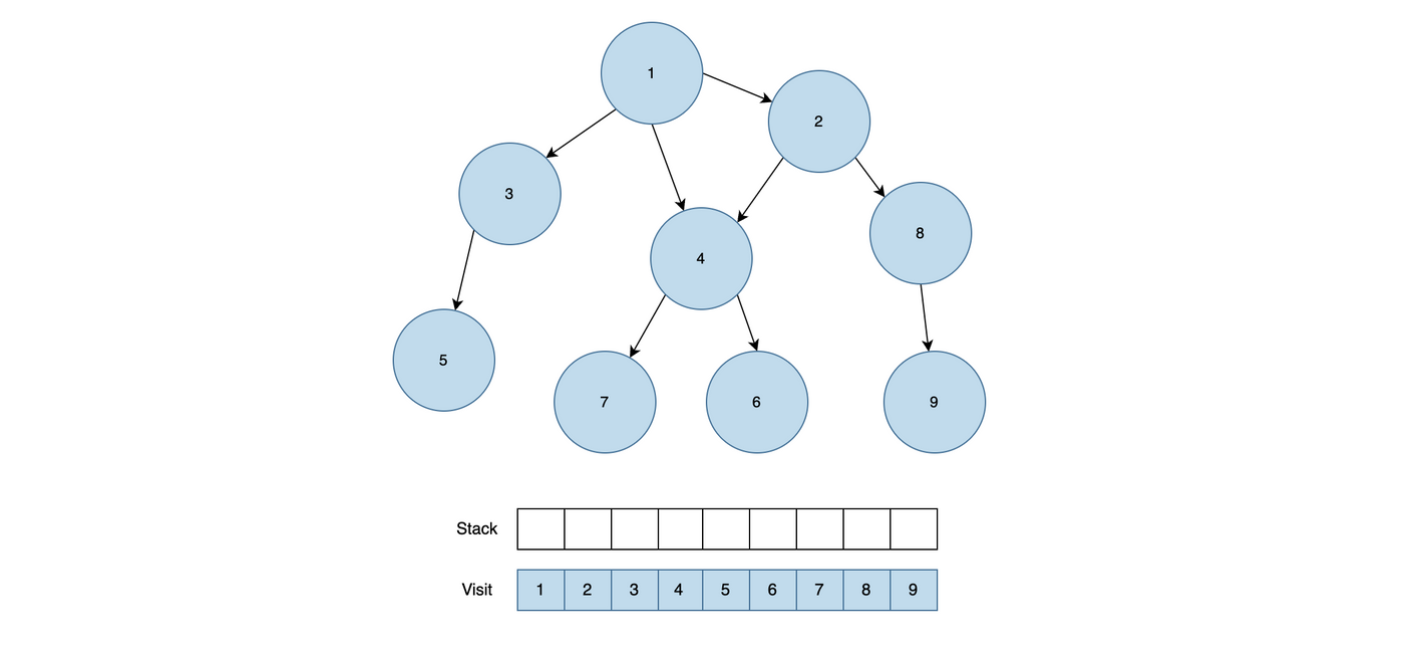
- 직원 한 명을 뽑는다. (왼쪽 제일 아래 있는 직원 부터 탐색)
- 뽑은 직원의 상사 직원을 가져온다.
- 상사 직원 객체에서 오늘의 날짜(R)에 맞는 남아있는 일에 대한 Queue를 가져와서 부하 직원의 남아있는 일에 대한 Queue에서 하나 뽑아서(poll) 상사 직원 객체의 Queue에 offer() 해준다.
- 위와 같은 로직을 반복하여 직원 번호가 0인 직원한테 처리된 업무 번호들을 answer에 누적하여 더해준다.
- 직원 번호가 0인 직원은 가장 위에 있는 대장 직원이기 떄문에 문제에서 요구하는 것이 제일 위에 있는 대장 직원에 의해 처리된 업무 번호들을 더해서 출력하는 문제이다.
제출 답안
import java.util.*;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));
String[] HKR = bufferedReader.readLine().split(" ");
int H = Integer.parseInt(HKR[0]);
int K = Integer.parseInt(HKR[1]);
int R = Integer.parseInt(HKR[2]);
int answer = 0;
List<Employee> list = new ArrayList<>();
List<Integer> index = new ArrayList<>();
for (int i = (int)Math.pow(2, H) - 1; i < (int)Math.pow(2, H + 1) - 1; i++) {
Employee employee = new Employee(i, false);
for (String str : bufferedReader.readLine().split(" ")) {
employee.remainTask.get(0).offer(Integer.valueOf(str));
}
list.add(employee);
index.add(i);
}
for (int i = 1; i < R + 1; i++) {
int size = list.size();
for (int j = 0; j < size; j++) {
Employee employee = list.get(j);
if (employee.getRemainTask(i).isEmpty()) {
continue;
}
if (employee.employeeNumber == 0) {
answer += employee.getRemainTask(i).poll();
continue;
}
int superiorNumber = employee.getSuperiorNumber();
Employee superior;
if (index.contains(superiorNumber)) {
superior = list.get(index.indexOf(superiorNumber));
} else {
superior = new Employee(superiorNumber, true);
list.add(superior);
index.add(superior.employeeNumber);
}
if (employee.employeeNumber % 2 == 0) {
superior.remainTask.get(1).offer(employee.getRemainTask(i).poll());
} else {
superior.remainTask.get(0).offer(employee.getRemainTask(i).poll());
}
}
}
System.out.println(answer);
}
}
class Employee {
int employeeNumber;
boolean isSuperior;
List<Queue<Integer>> remainTask;
public Employee(int employeeNumber, boolean isSuperior) {
this.employeeNumber = employeeNumber;
this.isSuperior = isSuperior;
remainTask = new ArrayList<>();
if (isSuperior) {
remainTask.add(new LinkedList<>()); // 왼쪽 직원이 올린 일
remainTask.add(new LinkedList<>()); // 오른쪽 직원이 올린 일
}
if (!isSuperior) {
remainTask.add(new LinkedList<>()); //
}
}
public int getSuperiorNumber() {
if (employeeNumber % 2 != 0) {
return (employeeNumber - 1) / 2;
}
return (employeeNumber - 2) / 2;
}
public Queue<Integer> getRemainTask(int date) {
if (isSuperior) {
if (date % 2 != 0) {
return remainTask.get(0);
}
return remainTask.get(1);
}
return remainTask.get(0);
}
public String toString() {
return String.valueOf(employeeNumber);
}
}
🤔 FeedBack
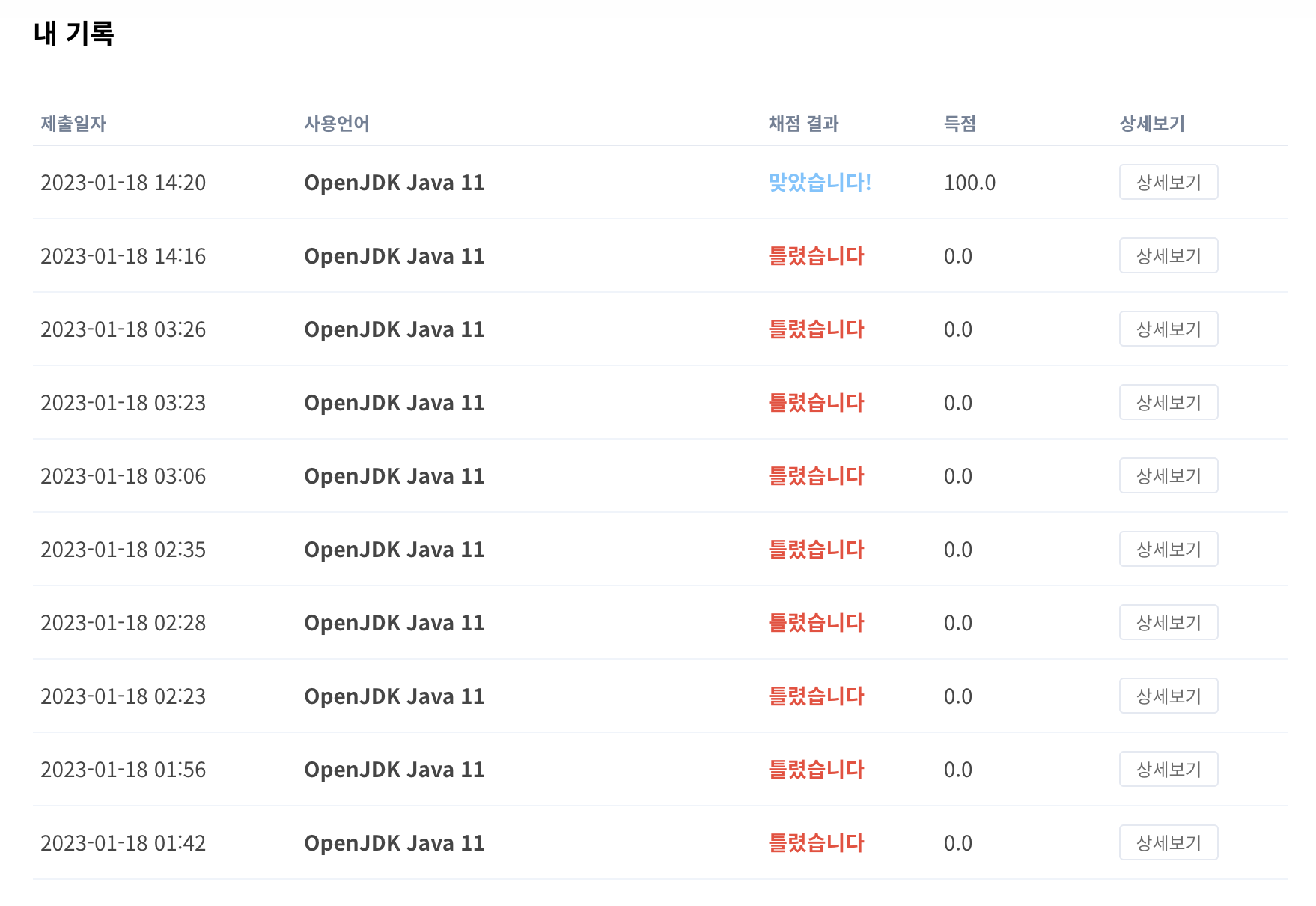
결과를 보면 정말...집착으로 풀기도 했고, 코드도 가독성이 많이 떨어지는 건 맞다. 그래도 "맞앗습니다!" 이 글자가 보였을 떄...정말...짜릿했다.
처음에 소프티어에 홈페이지에 들어가서 Practice를 누르고 제일 위에 있는거 풀어봐야겠다 하고 시작한 것이... 맨날 프로그래머스 레벨 1, 2 풀다가 소프티어 문제 풀고 있는데 안 풀려서 이거 뭐야 하고 있었는데 난이도가 별 3개였다...
이미 시작해버렸고...끝은 봐야되기 때문에 계속해서 문제를 풀었다. 믿기지 않겠지만 3시26분까지 계속 하다가 해결이 안돼서 찝찝하게 누웠고, 자기 전에도 계속 생각했다.
일어나서 생각한대로 코드 쭉 작성해보니깐 웬걸 "런타임 에러" 몇 개 빼고는 모두 정답이 나왔다. 오...이거 예외 하나만 잡아주면 통과될 거 같았다. 예상했던대로 나는 Queue를 사용했기 때문에 poll() 메서드를 사용하는데 있어서 예외가 발생해서 런타임 에러가 발생했던 거 같아서 모든 poll() 메서드 앞에 isEmpty()를 사용해서 예외처리를 해줬더니..통과됐다. 😂

'🧑🏻💻 Dev > 알고리즘' 카테고리의 다른 글
| [프로그래머스] 혼자서 하는 틱택토 Java (0) | 2023.03.20 |
|---|---|
| [프로그래머스] 레벨 1 문제 모두 풀고난 후 배운점 (2) | 2023.03.17 |
| [프로그래머스] 시소 짝꿍 (Java) (0) | 2023.02.15 |
| [Sorfteer] 인증평가(5차) 기출 - 성적 평가 (Java) (0) | 2023.02.07 |
| [Sorfteer] Level 2 문제 풀이 후 정리 (Java) (0) | 2023.02.03 |