추가적으로 Nest 공식문서를 더 살펴보면 nest start의 --watch 옵션은 Watch 모드로 실행을 해서 Live Reload를 해주는 옵션이라고 합니다. 그래서 로컬에서 npm run start:dev로 실행을 한 후 코드에 변경이 생기면 자동으로 변경을 적용해 주는 것이 이 옵션 덕분입니다.
2. node dist/main
NestJS는 javascript로 컴파일되어 Node.js 환경에서 실행이 됩니다. npm run build를 실행하면 nest build 명령어가 실행되며 NestJS 프로젝트가 빌드됩니다. 이때 루트 경로에 dist라는 폴더를 만들게 됩니다. 빌드되고 번들링 된 파일들이 이 dist 폴더 안에 저장됩니다.
프로젝트는 보통 main이라는 곳을 시작점으로 해서 Application을 실행하게 됩니다. Nest JS도 이 main.js에서부터 Application이 실행됩니다. node dist/main은 빌드된 파일 중 Application을 시작하기 위한 main.js를 실행하는 명령어입니다.
즉, node dist/main을 사용하기 위해서는 nest build와 같은 빌드 명령어가 선행되어야 합니다.
3. 결론
코드 변경을 감지하고, Live Reload를 통해서 개발 효율을 높이기 위해서 nest start --watch를 사용할 수 있습니다. 코드 변경에 대해서 직접 build를 하고, 다시 시작하면서 코드를 테스트하지 않아도 됩니다. 그래서 start:dev에서는 nest start --watch를 사용합니다.
운영 환경에서는 Live Reload가 필요하지 않습니다. 그리고 직접 build를 하는 경우가 대부분이기 때문에 빌드된 파일인 dist/main을 실행만 해주면 됩니다. 그렇기 때문에 start:prod에서는 node dist/main을 사용합니다.
start:prod에서도 nest start를 사용한다면 프로젝트 실행을 할 수는 있겠지만, build 과정을 두 번 거치는 경우가 발생할 수 있습니다. 보통 서버에 배포해서 build를 진행하고, build에 실패하면 Application을 실행하면 안 됩니다. 그렇기 때문에 의도에 맞게 적절하게 사용해야 할 것 같습니다.
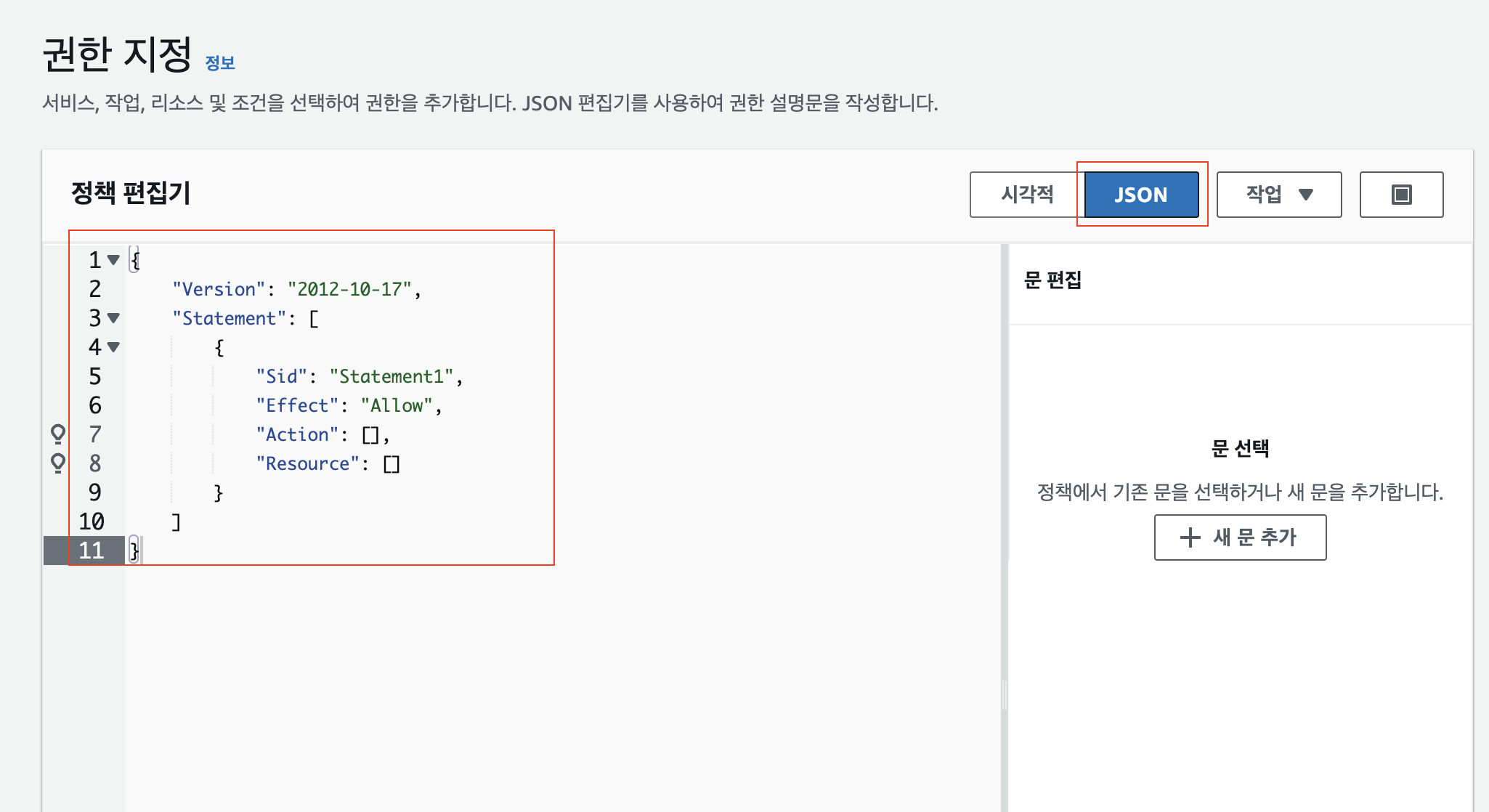
Sid가 있는 객체 하나하나를 Statemen라고 합니다. Sid는 해당 Statement를 식별하는 id 값입니다. 여러 개의 Statement를 입력해서 목적에 맞게 정책을 여러 개 추가할 수 있습니다.
먼저 AllowToAllBuckets는 모든 버킷에 접근할 수 있도록 허용한 것이고, AllowToAllObjects는 객체 리스트에 접근할 수 있고, AllowToGetPutDeleteObjects는 객체 조회, 수정, 삭제에 대한 정책입니다.
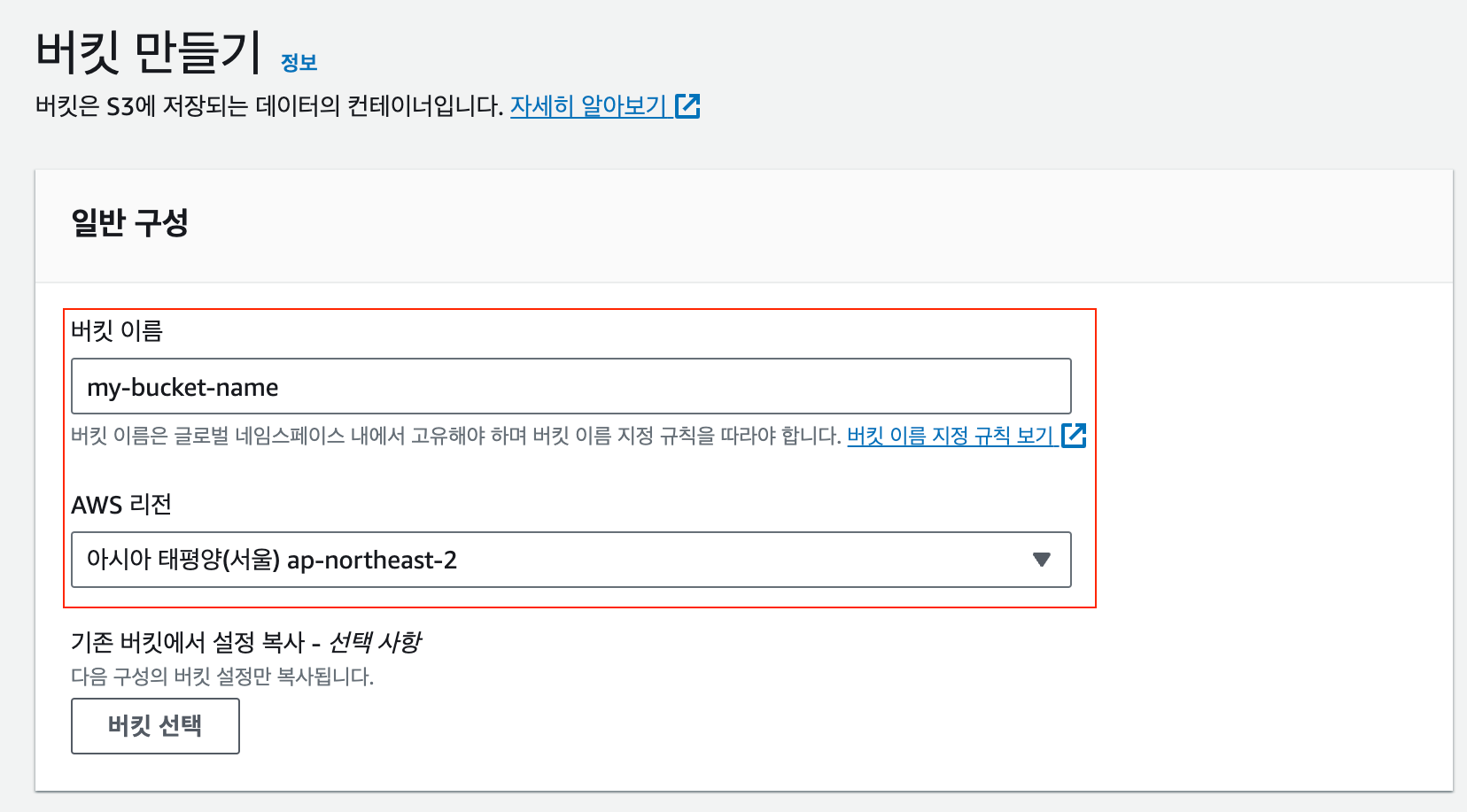
Resource에는 해당 Statement가 적용되는 대상을 적어줘야 합니다. "*"는 모든 대상을 의미하고, "arn:aws:s3:::my-bucket-name"은 제가 이번 포스트에서 생성한 "my-bucket-name"이라는 이름을 갖는 버킷에 대해서만 적용되는 정책입니다.
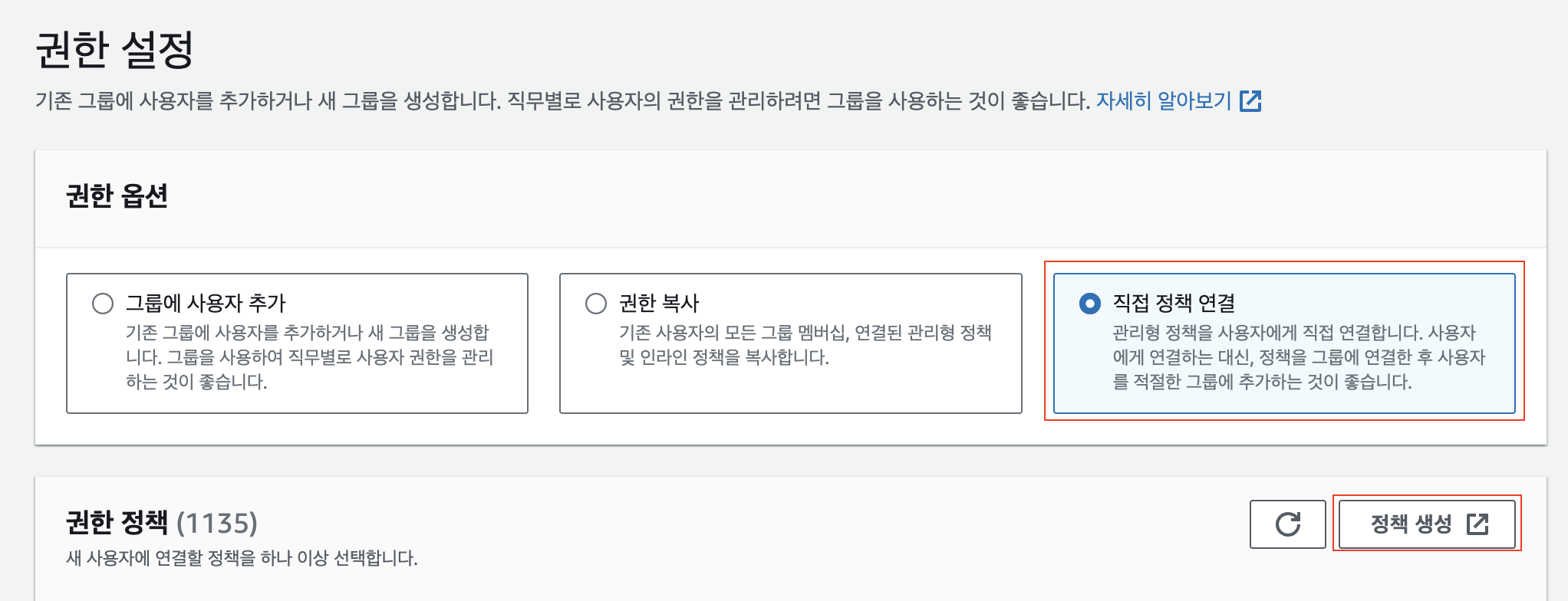
이렇게 정책 생성을 완료하고, 다시 IAM 생성 과정으로 넘어가서 만들었던 정책을 검색해서 선택한 후 내가 만들고 있는 IAM 사용자에게 내가 만든 정책을 적용시킵니다.
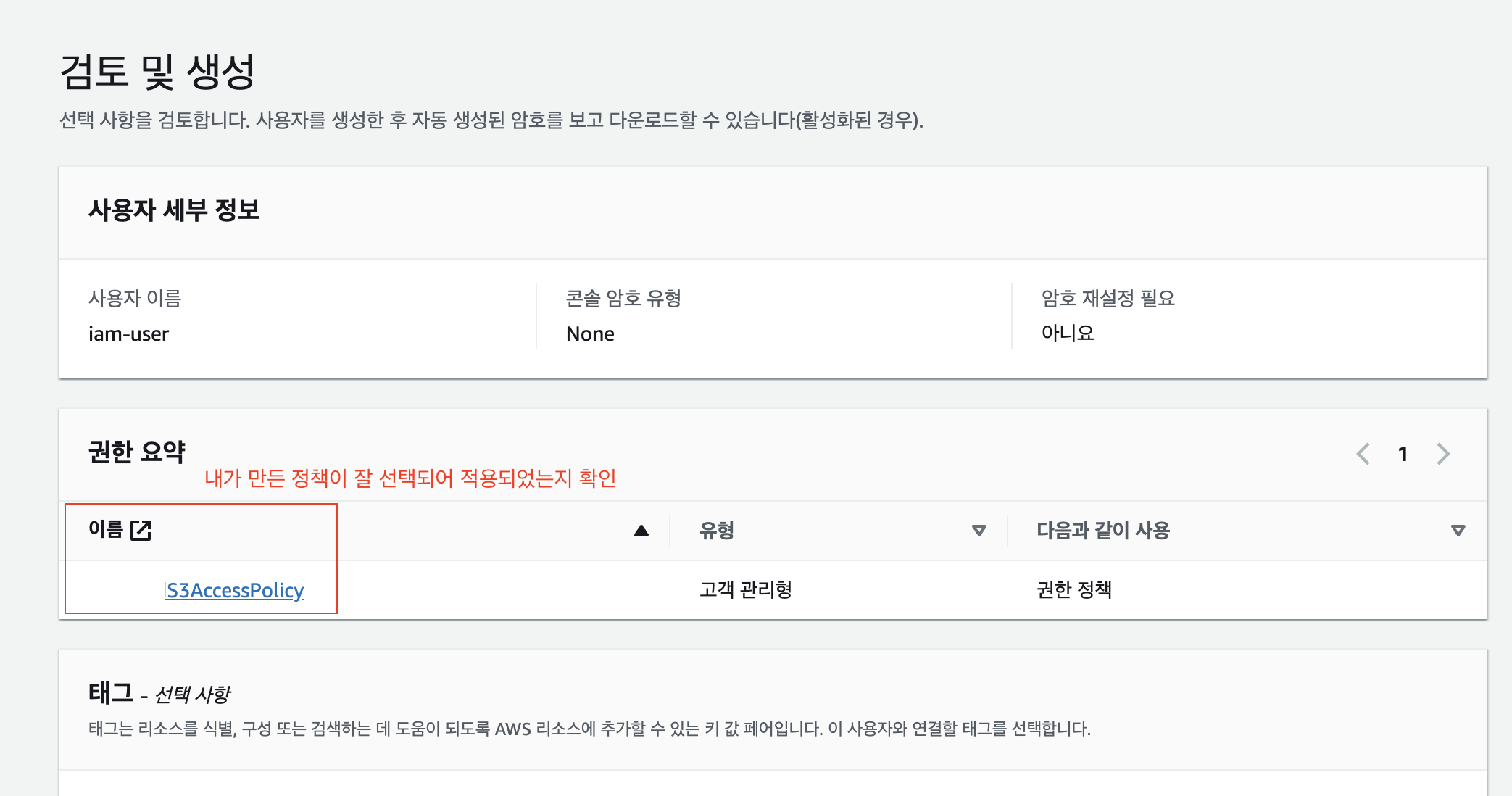
IAM 사용자 검토, 정책 등록 확인
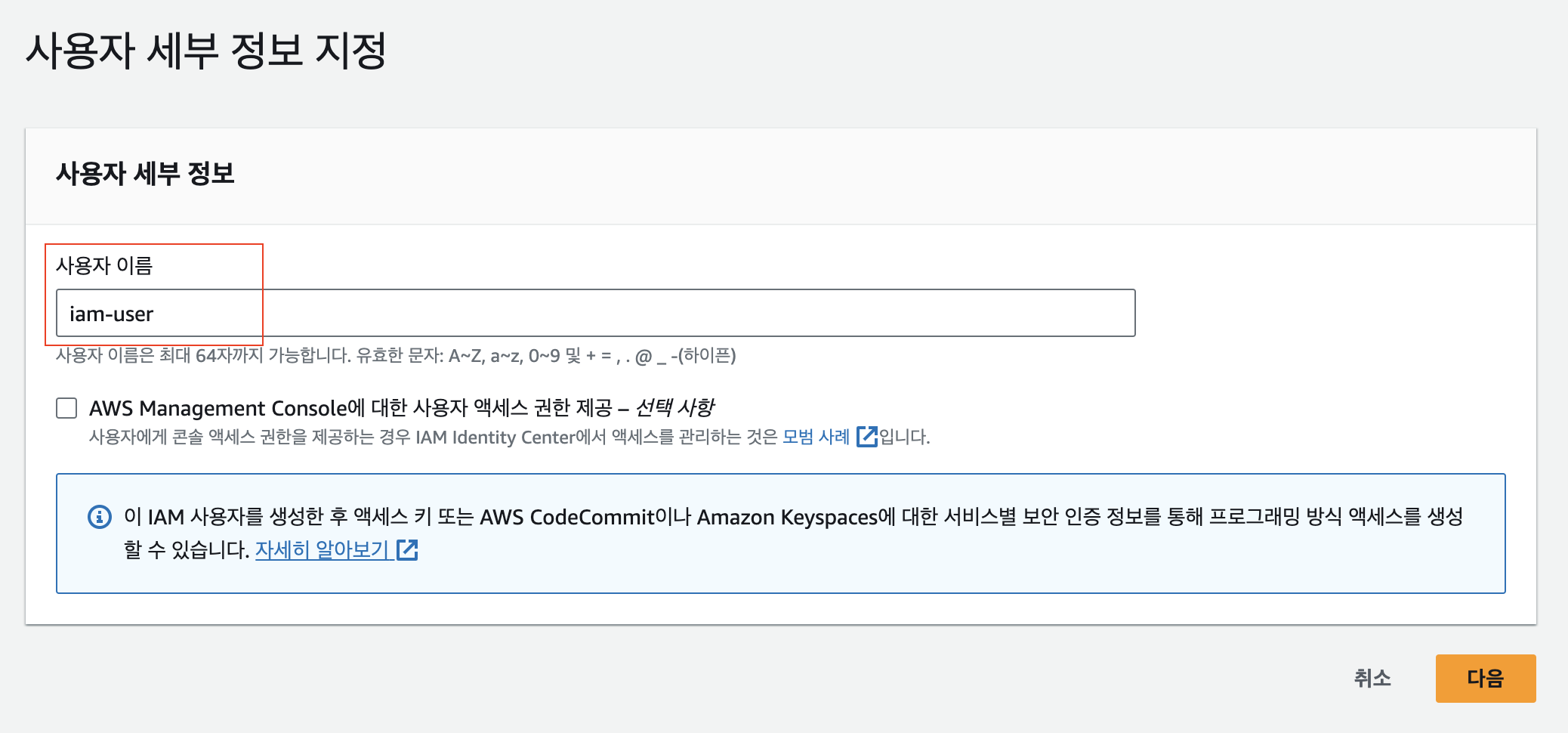
이제 다음으로 넘어가면 최종적으로 지금까지 만들었던 IAM 사용자의 내용을 검토할 수 있습니다. 여기서 내가 생성해서 적용해 준 정책이 정상적으로 등록되었는지 확인합니다. 검토가 완료되었다면 "사용자 생성"을 통해서 IAM 사용자 생성을 완료합니다.
3. Access Key 발급
이제 IAM 사용자를 이용해서 Nest 프로젝트에 적용하기 위해서 필요한 Access Key를 발급해야 합니다.
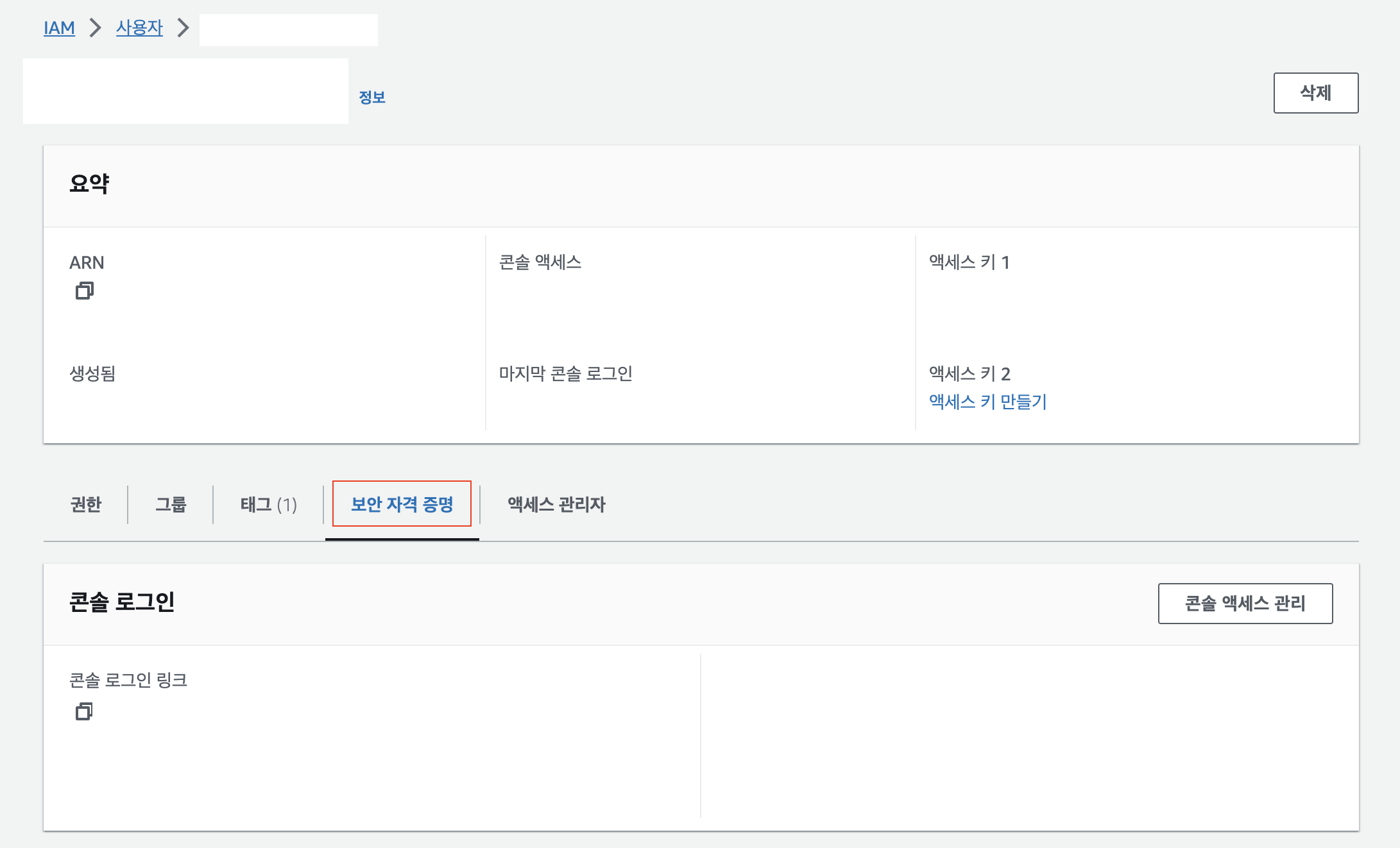
IAM > 사용자 > 보안 자격 증명
이제 생성한 IAM 사용자를 누르고 들어가서 밑에 "보안 자격 증명"이라는 버튼을 클릭합니다. 그리고 쭉 밑으로 내려봅니다.
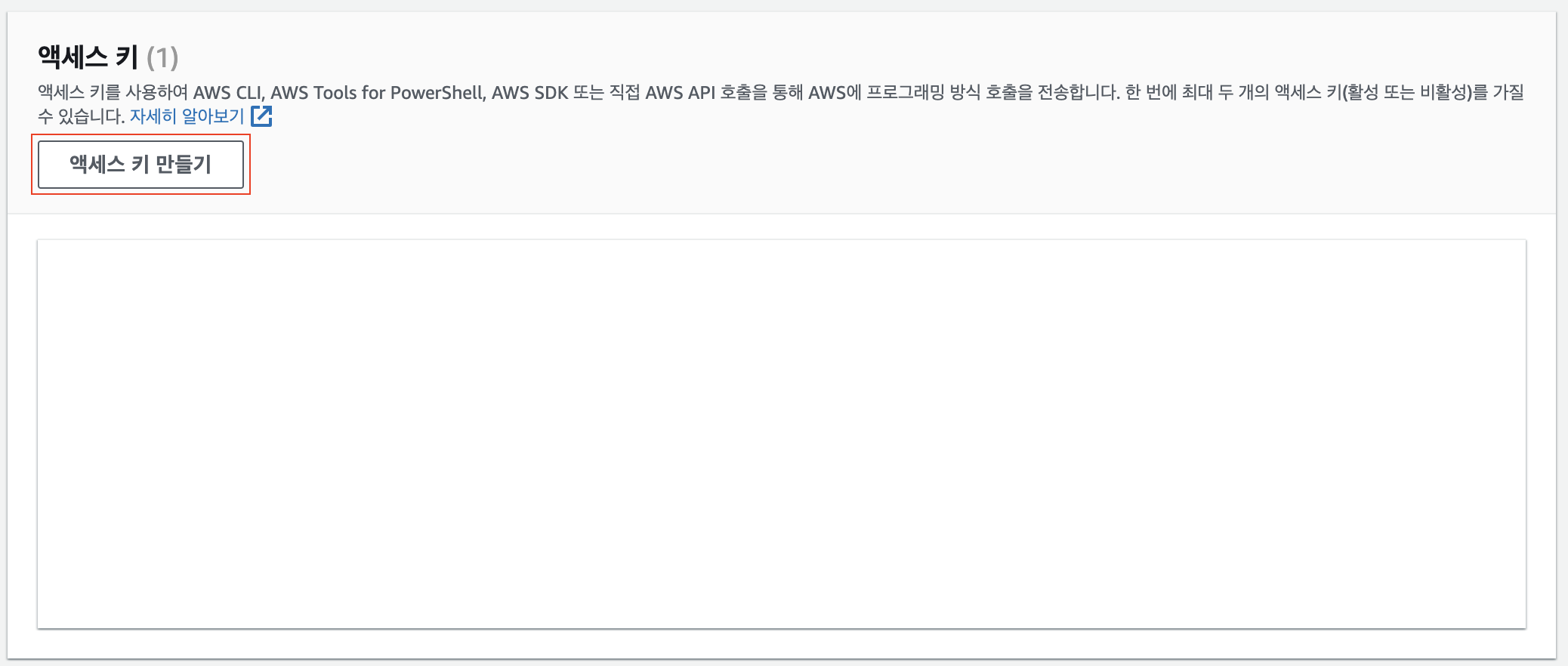
엑세스 키 만들기
밑에 내려보면 "액세스 키 만들기" 버튼이 있습니다. 눌러서 엑세스 키를 만들어줍니다.
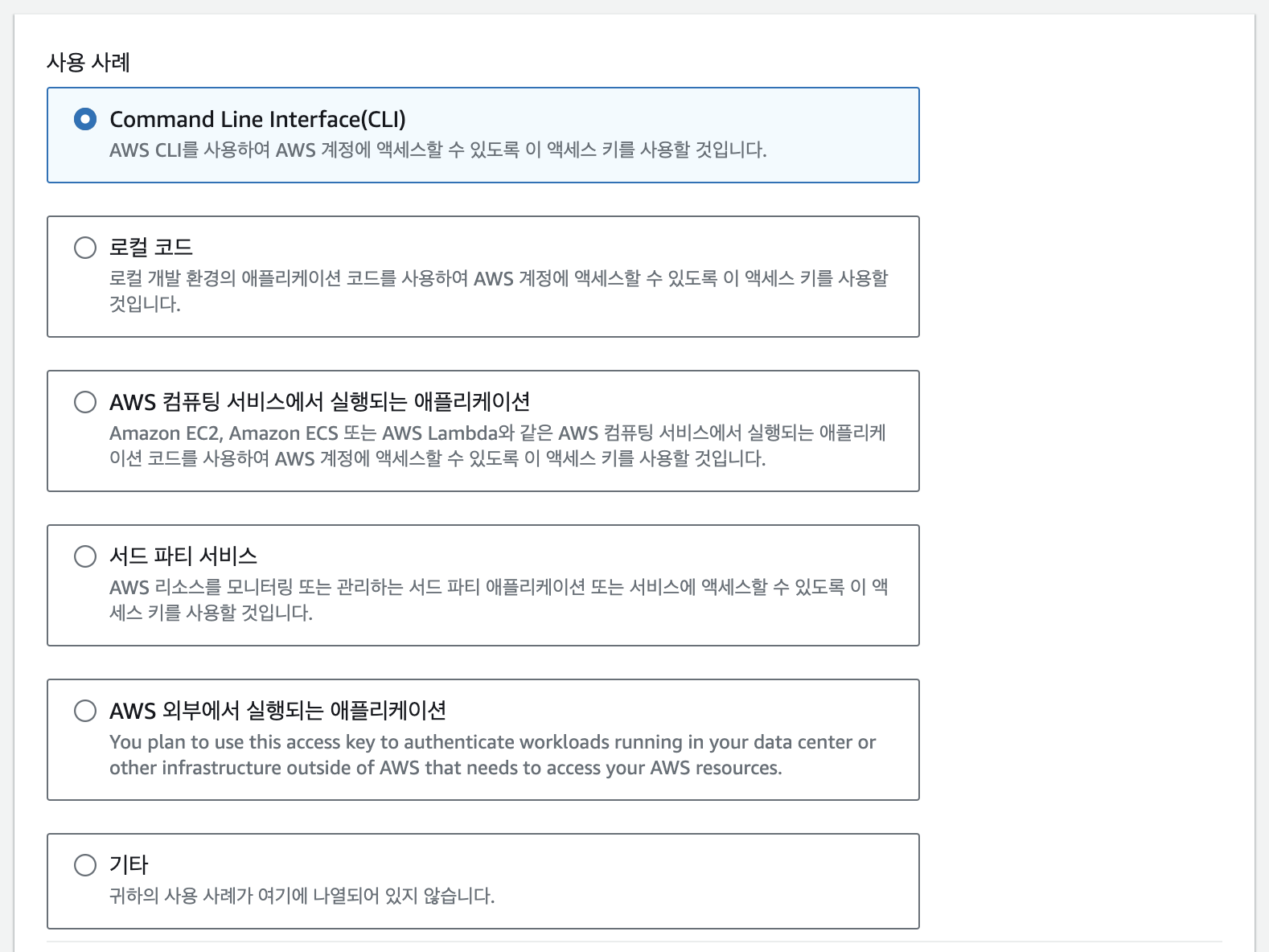
사용 사례
사용하시는 목적에 맞게 선택해 주시면 됩니다. 저는 CLI로 선택을 하고 넘어가겠습니다.
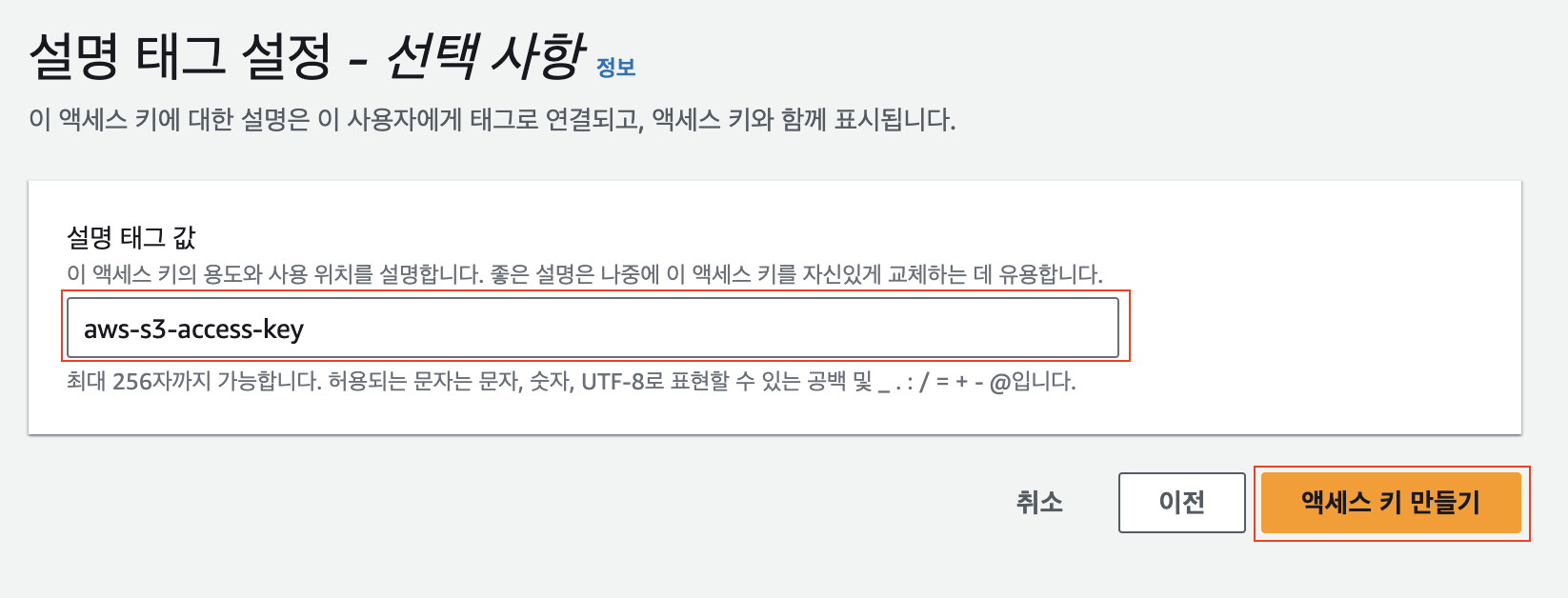
설명 태그 설정
선택 사항이기 때문에 작성하든 말든 상관없습니다. 저는 간단하게 "aws-s3-access-key"라고 적은 후 "액세스 키 만들기" 버튼을 눌러 생성을 완료하겠습니다. 생성 완료 후 "Access key ID"와 "Secret access key"를 확인할 수 있는데, CSV 파일을 저장해서 보관하시기 바랍니다. 나중에 Nest 프로젝트에 연결하기 위해서 필요한 정보입니다. 해당 정보는 노출이 절대 절대 안 되게 잘 관리해 주시길 바랍니다. Github에도 올라가지 않도록요!
4. Nest 프로젝트에 적용
이제 Nest 프로젝트에 적용하기 위해서 필요한 라이브러리를 설치해 줍니다.
npm install multer-s3 @aws-sdk/client-s3
.env 파일에 S3 관련 설정 정보를 입력합니다. (dotenv가 설치되어있다는 가정하에 진행합니다.)
# AWS S3 Properties
AWS_S3_BUCKET_NAME=my-bucket-name
AWS_REGION=ap-northeast-2
AWS_ACCESS_KEY_ID={엑세스 토큰 발급 시 받은 ACCESS KEY ID)
AWS_SECRET_ACCESS_KEY={엑세스 토큰 발급 시 받은 SECRET ACCESS KEY}
위에서 AWS_ACCESS_KEY_ID와 AWS_SECRET_ACCESS_KEY의 이름은 반드시 동일하게 작성해 주세요.
이제 Nest 프로젝트에서 S3의 이미지 저장 로직을 처리할 코드를 작성합니다. 저는 해당 이미지 저장 로직을 여러 곳에서 사용할 것이기 때문에 core 패키지의 utils에 만들도록 하겠습니다.
import { BadRequestException, Injectable } from "@nestjs/common";
import * as AWS from "aws-sdk";
import { PromiseResult } from 'aws-sdk/lib/request';
import * as path from "path";
@Injectable()
export class S3Service {
private readonly s3: AWS.S3;
private readonly MAXIMUM_IMAGE_SIZE: number;
private readonly ACCEPTABLE_MIME_TYPES: string[];
public readonly S3_BUCKET_NAME: string;
constructor() {
this.s3 = new AWS.S3({
region: process.env.AWS_REGION
})
this.MAXIMUM_IMAGE_SIZE = 3000000; // 이미지 용량 3MB 제한
this.ACCEPTABLE_MIME_TYPES = ['image/jpg', 'image/png', 'image/jpeg']; // 이미지 확장자 제한
this.S3_BUCKET_NAME = process.env.AWS_S3_BUCKET_NAME
}
async uploadToS3(file: Express.Multer.File): Promise<S3UploadResponse> {
try {
if (!this.ACCEPTABLE_MIME_TYPES.includes(file.mimetype)) {
throw new BadRequestException('이미지 파일 확장자는 jpg, png, jpeg만 가능합니다.');
}
if (file.size > this.MAXIMUM_IMAGE_SIZE) {
throw new BadRequestException('업로드 가능한 이미지 최대 용량은 3MB입니다.');
}
const key = `images/${Date.now()}_${path.basename(file.originalname,)}`
.replace(/ /g, ''); // 공백을 제거하기 위한 regex입니다.
const s3Object = await this.s3
.putObject({
Bucket: this.S3_BUCKET_NAME,
Key: key,
Body: file.buffer,
ContentType: file.mimetype
})
.promise();
const imgUrl = `https://${this.S3_BUCKET_NAME}.s3.amazonaws.com/${key}`;
return {
key: key,
s3Object: s3Object,
contentType: file.mimetype,
url: imgUrl
}
} catch (error) {
throw error;
}
}
}
export type S3UploadResponse = {
key: string;
s3Object: PromiseResult<AWS.S3.PutObjectOutput, AWS.AWSError>;
contentType: string;
url: string;
}
S3에 이미지를 업로드하는데 필요한 정보들을 S3Service에서 처리하고, 이미지를 업로드하는 메서드인 uploadToS3를 구현했습니다.
업로드 가능한 이미지의 최대 용량은 3MB로 제한을 두고, 이미지 확장자는 png, jpg, jpge로 제한을 두었습니다.
위에서 보면 AWS_ACCESS_KEY_ID와 AWS_SECRET_ACCESS_KEY에 대한 설정을 해주지 않는 것을 볼 수 있습니다. 실제로 accessKeyId라고 코드를 쳐보면 deprecated 되었다고 합니다. env 파일에 AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY라는 이름으로 만들어 두면, S3에 요청할 때 알아서 확인을 한다고 합니다. (싱기방기)
import { Module } from '@nestjs/common';
import { S3Service } from './utils/s3.service';
@Module({
providers: [S3Service],
exports: [S3Service]
})
export class CoreModule {}
이제 S3Service를 CoreModule의 providers와 exports에 등록을 하고, 필요한 곳에서 CoreModule을 import 받아 사용할 수 있습니다. CoreModule을 @Global()로 만들어도 되지만, 일단은 직접 import로 주입하는 방법을 이용했습니다.
위 명령어를 터미널에 쳐보면 현재 설정되어 있는 힙 메모리를 확인할 수 있습니다. 확인해 보니 저는 495라고 떴습니다.
로컬에서는 동작이 됐으니 로컬에서 확인한 값과 동일한 수준까지 올려주기로 했습니다.
export NODE_OPTIONS=--max_old_space_size=2096
2096까지 올려서 다시 첫 번째 명령어로 495에서 2096으로 변경된 것을 확인할 수 있습니다.
이렇게 하고 수동으로 서버에 작성해뒀던 ./deploy.sh을 실행해서 빌드 성공 후 배포에도 성공을 했습니다.
3. 터미널을 재시작하면 설정이 초기화되는 문제
됐겠지 하고 작업 후에 다시 자동화 배포를 하는 과정에서 빌드 시 동일한 문제가 발생했습니다.
찾아보니 터미널에서 설정해줬던 "max_old_space_size=2096"이 터미널을 재시작하면 다시 초기화된다고 합니다.
그래서 프로젝트 규모가 커지면서 점점 더 많은 힙 메모리를 요구하게 되었지만, 기본적으로 설정된 힙 메모리는 512MB입니다.
Github Actions에서 SSH를 통해 서버에 접근하여./deploy.sh를 실행하도록 설정해뒀습니다.
배포 과정을 진행할 때마다 터미널에 새로 접근을 해서 2096MB이 아닌 512MB로 적용되어서 동일하게 빌드가 실패했습니다.
영구적으로 바꾸는 방법이 존재한다고는 하지만, 세상 일 어떻게 될지 모르니 일단 배포 스크립트인 deploy.sh에 들어가서 프로젝트 빌드를 시작하기 전에 "export NODE_OPTIONS=--max_old_space_size=2096" 명령어를 실행하도록 수정해서 빌드, 배포에 성공했습니다.
근본적인 문제 해결은 메모리 누수를 확인해서 메모리가 누수되는 부분을 분석하여 찾아내야 한다고 합니다. 하지만, 지금은 메모리 누수를 확인할 만큼의 프로젝트 규모가 되지 않았다고 생각을 해서 일단은 NodeJS의 힙 메모리 할당량을 늘리자는 판단을 했습니다.
로컬에서도 빌드되지 않을 정도가 된다면 메모리 누수 방법과 해결 방법을 알아두면 좋을 거 같아서 이 부분도 찾아서 공부해 볼 생각입니다. 미리미리 알아두면 언젠간 도움이 됩니다! 미리 대비합시다.
Nest로 진행하고 있던 프로젝트가 있었습니다. InternalServerError(500)가 터지면 디버깅을 하거나, 오류에 대응할 때 효율을 높일 수 있도록 로그를 파일에 남기려고 적용하고자 했습니다. Java에서는 LogBack으로 로그를 관리하는 것 같은데, Nest에서는 Winston이라는 라이브러리를 사용한다.
Service에서 발생 시키는 예외들을 한 곳으로 모아서 처리하기 위해서 ExceptionFilter를 구현하는 GlobalExceptionFilter를 구현했습니다.
InternalServerError(500)로서 error 로그를 찍는 경우를 아래와 같이 2가지로 정했습니다.
throw new InternalServerException()으로 던져져서 Status 코드가 500인 경우
예상하지 못한 곳에서 예외가 터져서 핸들링하지 못한 Exception인 경우
1번의 경우에는 의도적으로 InternalServerException을 이용해서 던지는 경우이기 때문에 api.error.log 파일에 로그를 저장했습니다. 반대로 2번의 경우에는 의도하지 않은 예외를 잡은 경우이기 때문에 basic.error.log 파일에 로그를 저장하도록 했습니다. 추가로 디버깅이 편리하도록 어느 API 요청에서 발생했던 예외인지 확인을 위해 Request URL도 함께 로그에 남겼습니다.
포맷에 combine()을 이용해서 timestamp를 찍는 방법도 있었는데, js-joda의 LocalDateTime.now()가 더 편하고, 코드로 봤을 때 직관적인 것 같아서 simple() 포맷을 사용해서 로그를 남겼습니다. Winston Github 링크에 가보면 다양한 포맷에 대한 설명이 있습니다. 의도에 맞게 사용하시는 것을 추천합니다.
logs 디렉터리 내부에 생긴 log 파일 2개
이렇게 하고 재시작을 하면 logs/api.error.log와 logs/basic.error.log 파일이 생깁니다. 이제 해당 필터를 거치게할 Controller에 @UseFilters()를 붙여서 테스트를 해봐야 합니다. 500 에러가 발생하도록 해서 로그가 파일에 정상적으로 찍히는지 확인해봅시다.
@UseFilters(GlobalExceptionFilter)
@Controller('letters')
export class LettersController {
// 코드 생략
}
로그 확인하기
500 Internal Server Error 발생
위에서 Postman을 통해 확인한 Internal Server Error입니다. 이는 throw new InternalServerException을 통해 의도된 에러였기 때문에 api.error.log에 저장됩니다. 정상적으로 저장이 됐는지 확인해 봅니다.
logs/api.error.log 파일
정상적으로 저장됐습니다. 의도했던 error 로그가 파일에 찍혀서 저장된 것을 확인할 수 있습니다.
3월부터 시작해서 벌써 7개월이 지나 마지막 날이 되었습니다. 짧다고 하면 짧고, 길다면 길 수 있는 시간이 지났습니다.
"10월이 되면 조금 성장해 있을까?"라는 생각을 하면서 부트캠프에 참여했던 거 같습니다.
7개월 동안 부트캠프에서 진행했었던 프로젝트의 과정을 기록해보려고 합니다.
첫 번째 프로젝트
첫 번째 프로젝트는 개인 프로젝트였습니다. Java만을 이용하여 콘솔로 입력을 받고, 콘솔에 출력을 하는 "스마트 스토어"를 만드는 프로젝트였습니다. 이 프로젝트에서는 List, Map, Set과 같은 컬렉션 프레임워크의 사용이 금지되었습니다. 즉, 사용할 거면 직접 구현해서 사용했던 프로젝트입니다. 평소에 편리하게 그냥 가져다 쓰던 List, Map, Set 등 편리한 컬렉션들이 어떻게 작동되는지 느껴볼 수 있었던 프로젝트였습니다.
다른 부트캠프에 비해서 제가 참여했던 패스트캠퍼스에서는 Java 언어 수강 기간이 꽤나 큰 비중을 차지했었습니다. 강사님의 강의는 대부분 라이브 코딩을 통해서 진행되었고, 중간에 받은 질문이나 오류들을 같이 트러블 슈팅하며 꽤나 깊은 영역까지 확인해 보며 학습할 수 있었던 거 같습니다. 하지만, 트러블 슈팅에 시간을 많이 쓰셔서 진도를 제시간에 나가지 못하는 경우도 꽤나 있어서 불만이 있는 수강생분들도 있었던 것으로 기억합니다. 저는 개인적으로 문제 해결 능력을 기를 수 있었던 재미있는 수강 시간이었던 것 같습니다.
두 번째 프로젝트
두 번째 프로젝트는 "야구관리 프로그램"이었습니다. Java와 JDBC 그리고 Database(MySQL)를 이용하는 토이 프로젝트였습니다. 데이터베이스 설계에 대한 이론 강의를 진행한 후에 프로젝트가 진행되어 직접 요구사항에 대한 데이터베이스 설계를 해 볼 수 있었습니다.
경기장, 팀, 선수, 퇴출 선수에 대한 테이블을 설계했고, 요구사항에 맞게 비즈니스 로직을 Service에 구현했습니다. 두 번째 프로젝트에서는 두 명이서 팀을 이뤄서 진행한 첫 번째 팀 프로젝트였기 때문에 Github Commit Message Convetion을 정하고, Pull Request를 이용해서 Rebase Merge를 하는 방식으로 프로젝트를 진행했습니다. 야구 관리 프로그램을 진행할 때, 패키지 설계에 대한 고민도 했었습니다. 이때는 기능을 기준으로 db, dto, model, service, view 이렇게 패키지를 분리해서 작업을 했었습니다.
독학할 때, 유튜브로 봤었던 최주호 강사님이 데이터베이스 수업을 맡아주셨었는데 수업을 하실 때 적절한 비유를 통해서 이해를 쉽게 할 수 있도록 도와주셨던 것 같습니다. Index에 대한 개념, Index는 언제 사용하면 좋을지, OneToOne, OneToMany, ManyToOne, ManyToMany 등 여러 가지 의존 관계에 대해서 배울 수 있었습니다. 지금까지도 유용하게 잘 사용하고 있는 지식들입니다.
세 번째 프로젝트는 그 유명한 "게시판" 프로젝트입니다. 드디어 Springboot를 사용하기 시작한 토이 프로젝트입니다. Spring Data JPA와 MyBatis에 대한 이론 강의를 진행한 후 프로젝트가 진행되어 요구 사항에서는 사용자 서버는 Spring Data JPA를 이용하고, 관리자 서버는 MyBatis를 사용하라는 요구 사항이 있었습니다. 백엔드 팀원끼리 진행했던 프로젝트였기 때문에 View는 Thymeleaf와 Bootstrap를 이용하여 Server Side Rendering을 했습니다.
세 번째 프로젝트에서 사용자 서버와 관리자 서버를 따로 분리해서 API 통신을 할지 아니면 멀티 모듈로 구성해서 Entity들을 공유하여 사용할지 결정해야 했었습니다. 관리자의 기능은 사용자 기능이 완료된 후에 함께 구현하기로 했었기 때문에 프로젝트의 남은 기한을 고려했을 때, 새로운 저장소를 만들어 서버 자체를 분리하는 데는 무리가 있다고 판단하여 멀티 모듈로 사용자는 8080 포트, 관리자는 8081 포트로 분리하기로 결정했습니다.
두 번째 프로젝트에서 유용하게 사용했었던 Github Convention과 Pull Request & Rebase Merge 전략을 그대로 가져와서 새로운 팀원들과 살을 붙여 이용했습니다. 추가로 작업 내용을 Issue화 해서 협업을 진행했습니다. Commit Message에 Issue 번호를 적어서 작성하면 어떤 작업에서 발생된 Commit 내용인지 빠르게 파악할 수 있어서 좋았습니다.
개인적으로 멀티모듈이 생각했던 거보다 구성하는 것이 힘들었고, 패키지 구조가 복잡해지고 내가 찾고자 하는 클래스 파일을 찾는데 힘들었던 것 같습니다. 다음 프로젝트에서 같은 상황이 존재한다면 서버 자체를 분리하고, API 통신을 하지 않을까라는 생각을 하게 되었던 프로젝트였습니다.
네 번째 프로젝트는 "연차 & 당직 프로젝트"였습니다. 이번 프로젝트는 처음으로 프런트 개발팀과 함께 진행했던 협업 프로젝트였습니다. 처음 진행하는 협업 프로젝트여서 협업 특강을 따로 진행해 주었고, 요구사항도 그렇게 어렵지 않고 간단했습니다.
처음 하는 협업 프로젝트여서 지금까지 했던 방향과는 다르게 진행했습니다. 싱크업 미팅을 가진 후 프런트엔드 팀과 함께 먼저 주어진 기획을 가지고 와이어프레임을 작성했습니다. 와이어프레임을 함께 작성했던 이유는 요구 사항도 많지 않았고, 서로 생각하고 있는 개발 방향을 맞추기 위해서였습니다. 같은 기획서를 가지고, 다른 방향으로 충분히 생각할 수 있기 때문에 의견을 맞추는 것이 우선 되어야 한다고 생각했습니다.
와이어프레임을 작성한 후 백엔드 팀원끼리 모여 ERD 설계를 진행하고, API 명세서도 프런트 엔드 팀원분들과 함께 작성했습니다. 둘 다 처음 하는 협업이어서 어떤 Request를 받고, 어떤 Response를 줘야 할지에 대해서 의논했습니다. 처음 했던 협업 치고는 순탄하게 진행되었던 거 같습니다.
이번 프로젝트에서 새롭게 해 볼 수 있었던 것은 AWS Lightsail과 FileZilla를 가지고, 서버를 실제로 배포해 보는 경험을 해볼 수 있었습니다. 그리고 클라이언트 서버(HTTPS)와의 통신을 위해서는 SSL 인증서를 발급받아 도메인을 구매한 후 연결을 했어야 했습니다. 도메인은 가비아에서 저렴하게 구입했고, LetsEncrypt를 이용하여 인증서를 발급하고, application.yml에 설정을 추가해 줌으로써 프로젝트를 진행할 수 있었습니다.
다섯 번째 프로젝트는 "기업연계" 프로젝트였습니다. 지금까지 했던 4개의 프로젝트는 이 파이널 프로젝트를 위한 발판이라고 할 수 있습니다. 진행되는 과정은 연계된 기업의 대표분들이 직접 어떤 설루션을 해결해줬으면 하는지, 어떤 프로젝트를 진행하고 싶은지를 말하는 시간을 갖고 나서 1 지망, 2 지망, 3 지망 선택했습니다. 같은 기업을 선택한 사람들끼리 랜덤으로 팀이 구성되었습니다. 거의 모든 사람이 1 지망에 선택했던 프로젝트를 진행하셨던 거 같습니다. 기업연계 프로젝트는 PM, UX/UI도 합류를 하기 때문에 소통이 매우 중요했던 프로젝트였습니다.
패스트캠퍼스의 모든 프로젝트를 진행하며 조금 아쉽다고 생각되었던 부분이 팀을 랜덤으로 정해준다는 것이었습니다. 참여 점수, 성적 등을 고려하여 팀을 배정해 준다고는 하지만, 5~6개월이 지나는 동안 어느 정도 함께 해보고 싶은 사람들이 있다고 생각이 됩니다. 뭐 누구를 만나든 최선을 다해야 하는 것은 맞지만, 열정이 비슷한 사람들끼리 팀을 이루면 그 시너지 효과가 더욱 클 것이라고 생각되었기 때문입니다.
하지만, 불만과는 다르게 파이널 프로젝트에서 만났던 팀원분들은 열정이 넘치고, 오프라인 강의장까지 출석하시면서 함께 진행했습니다. 마지막 프로젝트이기 때문에 함께 이루고 싶은 팀의 공동 목표를 정했던 것 같습니다. 저희 팀에서 정한 공동 목표는 배포 자동화(CI/CD) 환경 구성, 테스트 커버리지 50% 이상 유지가 있었습니다.
실제로 프로젝트에서 Github Actions와 SSH를 이용하여 배포 자동화 환경을 구성했고, 테스트 커버리지는 57%를 달성했습니다. 그리고 새롭게 Java Code Convention도 정했습니다. 이때 나온 컨벤션이 거의 15개... 모두 다 지키지는 못했지만, 컨벤션을 정하는 과정에서도 배움이 있었습니다. 추가로 이번에는 Gitflow 전략을 도입하고, Rebase Merge 전략이 아닌 Squash Merge 전략을 사용했습니다. Squash Merge 전략을 사용한 이유는 하나의 작업에서 발생하는 Commit을 세분화하다 보니 너무 많은 Commit이 생겼고, 오히려 해당 작업을 추적하기가 어려워졌었습니다. 그래서 Squash Merge를 사용해서 세분화된 Commit들을 하나의 Commit으로 합쳐서 효과적으로 커밋을 관리하고, 가독성을 높일 수 있을 것이라고 생각했습니다.
처음에는 Github를 Push, Pull 정도만 이해하고 사용했었습니다. 프로젝트를 거치면서 Pull Request도 사용해 보고, 충돌을 해결하기 위해서 Rebase도 사용해 볼 수 있었습니다. 더 나아가 Issue를 적극적으로 사용하게 되었고, 마지막에는 Organization을 생성하여 Client와 Server를 함께 관리하고, 상황에 적절한 Gitflow 전략과 Merge 전략을 선택해서 사용할 수 있을 정도로 성장을 했습니다.
프로젝트를 진행하며 점점 필요에 의해서 기술을 학습했던 거 같습니다. 사실 패스트캠퍼스에서 제공되었던 실시간 강의는 개인적으로 조금 부실하다고 느껴졌었습니다. 글씨가 너무 작거나 짧은 시간에 너무 많은 정보를 제공하려고 해서 너무 복잡했던 거 같습니다. 그래서 달마다 지급되었던 지원금을 모아서 인프런에서 김영한 님의 강의를 구매해서 수강했었습니다. 필요하다고 생각될 때마다 HTTP 강의, Spring 강의, JPA, QueryDSL, MVC 모두 구매해서 수강하고, 바로 진행하고 있던 프로젝트에 활용해 보며 학습했습니다.
다음에 프로젝트를 진행한다면 Docker를 사용해서 배포환경을 구성해보고 싶습니다. 그리고 파이널 프로젝트에서 잠깐 사용했었던 JMeter를 조금 심오하게 사용해서 성능 개선도 해보고 싶다는 목표가 생겼습니다. 지금까지 프로젝트에서 문서화를 할 때 접근하기 좋았던 Notion을 주로 사용했지만, Swagger를 사용하여 API 문서화를 진행해보려고 합니다. 무조건 한다. 👊🏻
결국에는 스스로 하지 않고 가만히 있으면 가마니가 됩니다. 어느 곳을 가던 하는 만큼 얻어갈 수 있다고 생각합니다. 제가 열심히 하고, 열정적으로 참여하면 주변 사람들도 그런 사람들로 채워졌던 거 같습니다. 비전공자로 개발을 시작했지만, 10개월 동안 좋은 사람들과 함께 진행할 수 있어서 좋았던 활동이었다고 말할 수 있을 거 같습니다.
@NoArgsConstructor
public static class TestDTO {
private String testString;
private Integer testInteger;
public String toString() {
return "testString: " + this.testString + ", testInteger=" + this.testInteger;
}
}
toString()은 값이 제대로 바인딩되었는지 콘솔에서 확인하기 위한 용도입니다.
[결과]
>>> testString: null, testInteger=null
바인딩이 제대로 되지 않았습니다.
2. @NoArgsConstructor + @Getter
두 번째는 기본 생성자에 Getter를 붙여봅니다.
@Getter
@NoArgsConstructor
public static class TestDTO {
private String testString;
private Integer testInteger;
public String toString() {
return "testString: " + this.testString + ", testInteger=" + this.testInteger;
}
}
[결과]
>>> testString: 테스트, testInteger=100
바인딩이 제대로 되었습니다.
3. @NoArgsConstructor + @Setter
세 번째는 Setter와 생성자의 조합입니다.
@Setter
@NoArgsConstructor
public static class TestDTO {
private String testString;
private Integer testInteger;
public String toString() {
return "testString: " + this.testString + ", testInteger=" + this.testInteger;
}
}
[결과]
>>> testString: 테스트, testInteger=100
바인딩이 제대로 되었습니다.
여기서 중간으로 확인해야 할 것이 있습니다. 기본 생성자만 있을 때는 바인딩이 안 됐었는데, Getter나 Setter가 있으면 바인딩을 해줍니다. 한 가지 특별 케이스를 만들어봅시다.
4. @NoArgsConstructor + 커스텀 Getter
만약 Getter의 기능을 하는 다른 이름의 메서드를 만들고 싶어 졌다고 해봅시다.
"나는 get이라는 걸 안 쓰고 find를 써서 새롭게 만들어볼래." <-- 똑같은 건 싫어 싫어 개발자
@NoArgsConstructor
public static class TestDTO {
private String testString;
private Integer testInteger;
public String findTestString() {
return testString;
}
public Integer findTestInteger() {
return testInteger;
}
public String toString() {
return "testString: " + this.testString + ", testInteger=" + this.testInteger;
}
}
[결과]
>>> testString: null, testInteger=null
???... Getter와 똑같은 기능을 하는 메서드를 만들었는데 데이터가 정상적으로 바인딩되지 않았다. 그럼 여기서 또 궁금한 건 못 참는 피곤한 사람(나)들은 get이라는 이름으로 커스텀 메서드를 만들어봅니다. ㅎ
@NoArgsConstructor
public static class TestDTO {
private String testString;
private Integer testInteger;
public String getTestString() {
return testString;
}
public Integer getTestInteger() {
return testInteger;
}
public String toString() {
return "testString: " + this.testString + ", testInteger=" + this.testInteger;
}
}
[결과]
>>> testString: 테스트, testInteger=100
!!!? 바인딩이 되었습니다. 더 궁금한걸 못 참는 분들은 이미 해보시고 있겠지만, Setter도 동일합니다. bindTestInteger() 이런 식으로 Setter를 만들면 바인딩이 제대로 되지 않습니다.
그럼 여기서 얻어볼 수 있는 첫 번째 결론은 Getter 또는 Setter가 필요한데, 이름이 get 어쩌고, set 어쩌고여야 한다는 것입니다.
이 궁금점은 JackSon 홈페이지에 가보면 알 수 있습니다. 영어를 잘하는 분들은 이런 노가다짓은 안 하고 계시겠죠..? 흑 하지만... 재밌는 걸 어떡하죠. 🤥
To read Java objects from JSON with Jackson properly, it is important to know how Jackson maps the fields of a JSON object to the fields of a Java object, so I will explain how Jackson does that.By default Jackson maps the fields of a JSON object to fields in a Java object by matching the names of the JSON field to the getter and setter methods in the Java object. Jackson removes the "get" and "set" part of the names of the getter and setter methods, and converts the first character of the remaining name to lowercase. For instance, the JSON field named brand matches the Java getter and setter methods called getBrand() and setBrand(). The JSON field named engineNumber would match the getter and setter named getEngineNumber() and setEngineNumber().If you need to match JSON object fields to Java object fields in a different way, you need to either use a custom serializer and deserializer, or use some of the many Jackson Annotations.
Jackson에서 필드를 바인딩할 때 getter, setter 메서드에서 get, set 부분을 제거하고 첫 문자를 소문자로 변경하는 방식으로 해당 필드가 있는지 확인한다고 합니다. 즉, 해당 변수를 찾을 때 변수명을 확인하는 게 아니고 getter와 setter를 보고 해당 필드가 있는지 확인을 하고, 매칭한다는 것을 의미합니다.
5. Getter 테스트 (제일 재밌는 부분 😆)
Jackson에서는 getter, setter에서 get, set 부분을 제거하고, 첫 문자를 소문자로 변경하는 방식으로 해당 필드를 찾는다고 했습니다.
궁금한 건 못 참는 두 번째 테스트를 해봤습니다.
5.1 get + 소문자 시작
@NoArgsConstructor
public static class TestDTO {
private String testString;
private Integer testInteger;
public void gettestString() {
return testString;
}
public void gettestInteger() {
return testInteger;
}
public String toString() {
return "testString: " + this.testString + ", testInteger=" + this.testInteger;
}
}
CamelCase로 작성하기 때문에 이렇게는 안 적겠지만, 궁금해서 테스트해 봤습니다.
get을 제외하면 testString이고, 여기서 첫 문자를 소문자로 바꾸면 testString 그대로 이기 때문에 바인딩이 될 것이라고 예상했습니다.
[결과]
>>> testString: null, testInteger=null
바인딩이 정상적으로 되지 않았습니다.
5.2 get + 대문자 시작 + 소문자(두 번째 단어) (1)
이번에는 첫 문자는 CamelCase대로 대문자로 시작하고, 두 번째 단어를 소문자로 변경해 봤습니다.
@NoArgsConstructor
public static class TestDTO {
private String testString;
private Integer testInteger;
public String getTeststring() {
return testString;
}
public Integer getTestinteger() {
return testInteger;
}
public String toString() {
return "testString: " + this.testString + ", testInteger=" + this.testInteger;
}
}
[결과]
>>> testString: null, testInteger=null
역시나 바인딩이 되지 않았습니다. 위에 건 예상 못했는데, 이건 사실 예상을 했습니다.
JackSon에서 말하는 첫 문자를 소문자로 변경한다는 것이 어디까지를 말하는 것일지 궁금해서 더 테스트해 봤습니다.
5.3 get + 대문자 시작 + 소문자 시작(두 번째 단어) (2)
메서드 조건은 5.2와 동일하게 가져가고, 이번에는 변수 이름을 변경해 봤습니다.
@NoArgsConstructor
public static class TestDTO {
private String teststring;
private Integer testinteger;
public String getTeststring() {
return teststring;
}
public Integer getTestinteger() {
return testinteger;
}
public String toString() {
return "teststring: " + this.teststring + ", testinteger=" + this.testinteger;
}
}
[결과]
>>> teststring: 테스트, testinteger=100
바인딩이 되었습니다. 음 이쯤 되면 조금 억지스러운 테스트를 한번 해보려고 합니다.
5.4 get + 대문자 여러 개 + 소문자
@NoArgsConstructor
public static class TestDTO {
private String aBCdef;
private Integer ghijk;
public String getABCdef() {
return aBCdef;
}
public Integer getGHIjk() {
return ghijk;
}
public String toString() {
return "aBCdef: " + this.aBCdef + ", ghijk=" + this.ghijk;
}
}
저는 getABCdef()에서 get을 제외하면 ABCdef가 남고, 첫 문자를 소문자로 변경한다고 되어 있었습니다.
예상하는 건 "aBCdef라는 변수가 있으면 바인딩이 제대로 될 것이다."라는 가정을 하고 접근했습니다.
아래 있는 getGHIjk()는 get을 제외하면 GHIjk에서 처음으로 만나는 소문자 j 전까지를 한 문자로 본다고 생각하고, 적어봤습니다.
예상이 맞다면 ghijk라는 변수에 바인딩이 정상적으로 될 것입니다. 둘 중에 하나는... 맞겠지 🥺
[결과]
>>> aBCdef: null, ghijk=100
두두둥! 두 번째 예상이 맞은 거 같습니다. get을 제외하고, 그다음에 나오는 단어에서 첫 번째로 만나는 소문자 전까지의 대문자를 모두 소문자로 변경하는 것 같습니다.
5.5 진짜 정말 마지막 테스트
예상한 것이 맞는지 이해한 대로 마지막 테스트를 진행해 봅니다.
getter에서 get을 제외합니다.
나머지 단어에서 첫 번째 소문자가 나오기 전까지의 대문자는 모두 소문자로 변경합니다.
@NoArgsConstructor
public static class TestDTO {
private String abcdEFG;
private Integer abcDEFG;
public String getABcdEFG() {
return abcdEFG;
}
public Integer getabcDEFG() {
return abcDEFG;
}
public String toString() {
return "abcdEFG: " + this.abcdEFG + ", abcDEFG=" + this.abcDEFG;
}
}
첫 번째 변수를 제가 생각한 대로 변경해 보겠습니다. getABcdEFG에서 get을 제거하면 ABcdEFG가 됩니다.
여기서 처음으로 만나는 소문자(c) 전까지의 모든 대문자를 소문자로 변경하면 abcdEFG가 됩니다.
두 번째 변수를 제가 생각한 대로 변경해 보겠습니다. getabcDEFG에서 get을 제거하면 abcDEFG가 됩니다.
여기서 처음으로 만나는 소문자(a) 이전에는 대문자가 존재하지 않기 때문에 그대로 abcDEFG가 됩니다.
[결과]
>>> abcdEFG: 테스트, abcDEFG=100
정상적으로 바인딩이 되었습니다. 다음에는 @Builder, @AllArgsConstructor과 JackSon을 사용해 보고, 이번글에서 상세하게 정리해보지 못한 Setter 관련해서도 적어보려고 합니다. 시간이... 된다면?