캐시(cache)는 무엇일까?
캐시에 대한 정의를 먼저 알아보고 가야 할 것 같습니다. 캐시란 데이터나 값을 미리 복사해서 보관하는 임시 장소를 말합니다.
그럼 캐시를 왜 사용하는 걸까요?
캐시(cache)를 사용하는 이유?
같은 정보를 반복해서 읽어오는 경우가 있던가, 데이터에 접근하는데 시간이 오래 걸리는 데이터인 경우에 사용을 고려해볼 수 있습니다.
말 그대로 반복해서 가져오는 데이터를 복사해서 캐시에 저장해 두고, 호출될 때마다 캐시에 보관된 데이터를 빠르게 가져올 수 있습니다.
데이터에 접근하는 시간이 긴 경우도 해당 데이터를 미리 캐시에 복사해서 넣어두고, 호출하면 캐시에 보관된 데이터를 가져와서 사용합니다.
이렇게 해주면 I/O가 감소하고, 프로젝트의 성능을 올려줄 수 있습니다. 하지만 캐시를 사용할 때 고려해줘야 하는 점은 다음과 같습니다.
캐시가 있을 때, 없었을 때와 프로젝트의 기대 동작이 동일해야 합니다.
이제 코드 예시로 한번 살펴봅시다. 이번에 생각해본 시나리오는 온라인 서점에서 책(Book)의 정보를 조회할 때, 같은 책을 여러 번 조회하는 상황을 만들어볼 것입니다.
기대하는 결과는 최초에 요청된 Book만 Repository에 접근해서 데이터를 가져오고, 그 뒤에 들어온 요청의 경우에는 캐시에서 데이터를 가져와서 사용하는 것입니다.
필요한 기본 코드 작성
# Book.java
@NoArgsConstructor
@AllArgsConstructor(staticName = "of") // .of()로 Book 객체를 만들 수 있도록 해줍니다.
@Data
public class Book {
private String title;
private String author;
private String publishedDate; // 0000-00-00 형태의 문자열로 입력받음
}BookRepository에 제목(title), 저자(author), 출간일(publishedDate)를 받아서 저장합니다.
# BookRepository.java
@NoArgsConstructor
@Repository
public class BookRepository {
private Map<String, Book> bookShelf = new HashMap<>();
public void enrollBookInfo(String title, String author, String publishedDate) {
bookShelf.put(title, Book.of(title, author, publishedDate));
}
public Book getBook(String title) {
System.out.println(title + "을 찾기 위해서 데이터베이스에 접근....");
if (bookShelf.keySet().contains(title)) {
return bookShelf.get(title);
}
throw new RuntimeException("찾는 도서는 존재하지 않습니다.");
}
}enrollBookInfo()는 도서를 등록할 수 있는 메서드입니다. getBook()에서 찾고자하는 도서가 없다면 RuntimeException을 발생시키도록 설계해 봤습니다.
캐시는 Repository로 따로 들어오지 않기 때문에 만약 Service를 통해서 Repository에 접근했다면 "title을 찾기 위해서 데이터베이스에 접근...."이라는 메시지를 출력하도록 해놨습니다.
# BookService.java
@RequiredArgsConstructor
@Service
public class BookService {
private final BookRepository bookRepository;
@PostConstruct
public void init() {
// 도서 4개를 등록합니다.
bookRepository.enrollBookInfo("자바는 정석이다", "김정석", "2022-12-12");
bookRepository.enrollBookInfo("파이썬은 정석이다", "이정석", "2012-06-13");
bookRepository.enrollBookInfo("자바스크립트는 정석이다", "박정석", "2020-02-14");
bookRepository.enrollBookInfo("C는 정석이다", "정정석", "2015-01-11");
}
public void printBookInfo(String title) {
try {
Book book = bookRepository.getBook(title);
System.out.println("도서명: " + book.getTitle() + " 저자: " + book.getAuthor() + " 출간일: " + book.getPublishedDate());
} catch (RuntimeException exception) {
System.out.println(exception.getMessage());
}
}
}@PostConstruct 애노테이션을 이용하여 BookService의 생성자가 실행된 후에 바로 4개의 도서를 등록합니다. 이렇게 등록하면 BookRepository에 해당 책들이 등록됩니다.
그리고 조회에 사용할 때는 printBookInfo()를 이용하여 출력할 수 있도록 했습니다. 이때 Repository에서 발생시킨 RuntimeException에 대한 예외를 처리해 줍니다.
# MainApplication.java
@RequiredArgsConstructor
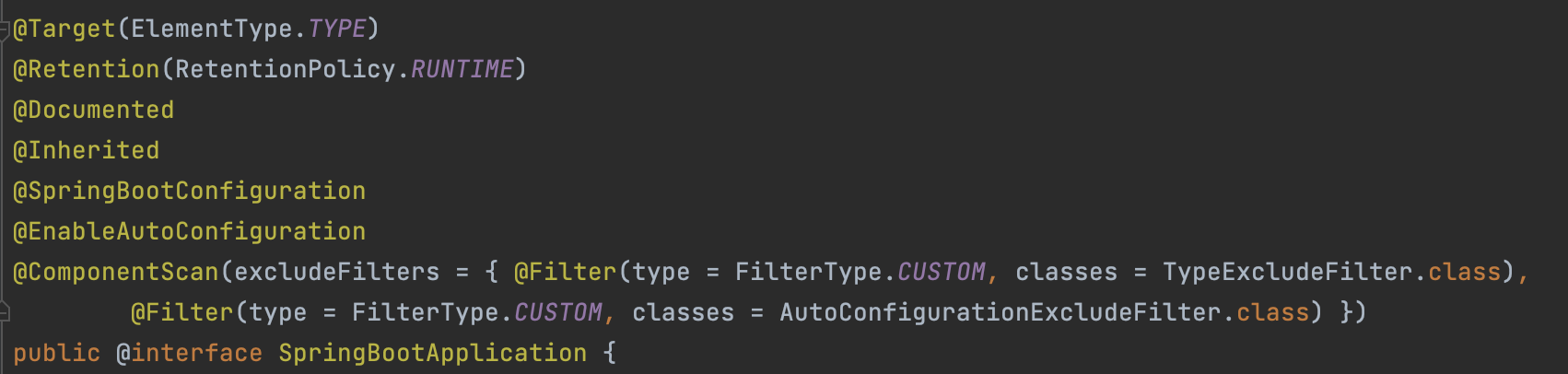
@SpringBootApplication
public class MainApplication {
private final BookService bookService;
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
@EventListener(ApplicationReadyEvent.class) // <-- 모든 빈이 다 등록이 끝났을 때의 이벤트를 말함
public void run() {
bookService.printBookInfo("자바는 정석이다");
bookService.printBookInfo("자바는 정석이다");
bookService.printBookInfo("자바는 정석이다");
bookService.printBookInfo("자바는 정석이다");
}
}BookService를 DI 받아서 "자바는 정석이다"라는 도서를 BookRepository에서 꺼내서 조회합니다. 해당 작업을 4번 연속으로 조회하는 작업입니다. 출력되는 결과를 한번 확인해 보겠습니다.
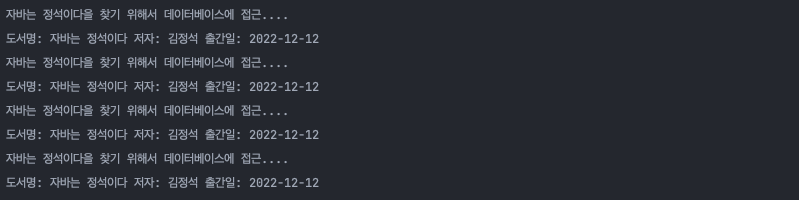
출력된 결과를 보면 "자바는 정석이다을 찾기 위해서 데이터베이스에 접근...."이라는 메시지가 4번 떴습니다. 그 말은 즉, "자바는 정석이다"라는 책을 4번 조회하기 위해서 BookRepository에 4번 접근했다는 것을 의미합니다.
그럼 이제 캐시를 사용해서 최초 접근에만 BookRepository에 접근하도록 설정해 봅시다. 만약 성공적으로 캐시가 작동했다면 기대하는 결과는 아래와 같습니다.
자바는 정석이다을 찾기 위해서 데이터베이스에 접근....
도서명: 자바는 정석이다 저자: 김정석 출간일: 2022-12-12
도서명: 자바는 정석이다 저자: 김정석 출간일: 2022-12-12
도서명: 자바는 정석이다 저자: 김정석 출간일: 2022-12-12
도서명: 자바는 정석이다 저자: 김정석 출간일: 2022-12-12
Redis 설치하기
Redis Homepage에 들어가면 각 운영체제마다 설치할 수 있는 방법이 있습니다. 이 부분에 대해서는 다루지 않겠습니다.
저는 Mac M1을 사용하고 있어서 homebrew로 간단하게 설치했습니다.
Redis 실행시키기 (터미널)
# Redis 서버 실행하기
>> redis-server --loglevel verbose

이렇게 입력해 주면 로컬에서 Redis Server를 여는데 성공했습니다. --loglevel verbose는 debug와 비슷하게 로그 내역을 상세하게 출력해 줍니다. 예를 들면 서버 접속 이력, 캐시 등록 이력 이런 내용이 모두 출력됩니다. 원한다면 특정 로그 레벨만 출력되도록 해줄 수 있습니다.
# Redis Client로 접속하기
열어둔 서버에 Client로 접속해 보겠습니다.
>> redis-cli
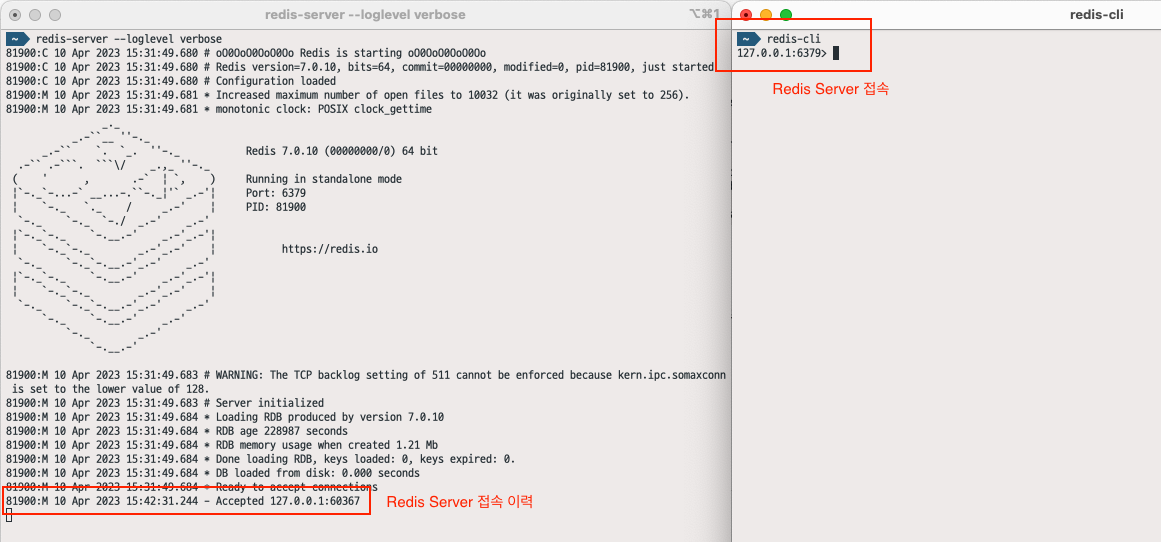
클라이언트로 Redis 서버에 접속하니 Redis 서버 쪽에서 이력이 남는 것을 볼 수 있습니다.
# Redis에 등록된 캐시(Key) 데이터 확인하기
>> keys *

등록된 모든 Key를 출력해 볼 수 있는 명령어입니다. 결과는 (empty array)라고 나와야 정상입니다. 저희는 아직 캐시를 사용하기 위한 설정을 하지 않았습니다. 이제 다시 프로젝트로 넘어가서 Redis를 사용하기 위한 설정을 해볼 것입니다.
Redis 의존성 추가하기
# build.gradle
implementation 'org.springframework.boot:spring-boot-starter-data-redis'dependencies에 해당 Redis 의존성을 추가해 줍니다. 아 참고로 저는 지금 스프링부트 2.5.2 버전에 자바는 11 버전을 사용하고 있습니다. 혹시나 스프링부트 버전이 많이 낮으신 분들은 Redis를 지원하는 버전인지 확인해 볼 필요가 있습니다. 대부분 2.5.2 이상은 쓰고 있을 것으로 판단됩니다.
어떤 부분에 캐시를 적용할지 찾고, 적용하기
우리가 캐시를 적용해야 하는 부분은 Repository에 접근하여 Book 정보를 가져오는 행위를 하는 곳에 캐시를 적용해야 합니다. 찾아보면 BookRepository의 getBook() 메서드에서 해당 역할을 담당하고 있습니다.
그럼 BookRepository의 getBook() 메서드에 캐시를 적용해 보겠습니다.
# getBook() in BookRepository.java
@Cacheable("book")
public Book getBook(String title) {
System.out.println(title + "을 찾기 위해서 데이터베이스에 접근....");
if (bookShelf.keySet().contains(title)) {
return bookShelf.get(title);
}
throw new RuntimeException("찾는 도서는 존재하지 않습니다.");
}@Cacheable() 애노테이션으로 캐시를 적용시켰습니다. 캐시에서 사용할 key 이름은 "book"으로 설정했습니다.
# MainAppalication.java에 @EnableCaching 적용하기
@EnableCaching
@RequiredArgsConstructor
@SpringBootApplication
public class MainApplication {
private final BookService bookService;
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
@EventListener(ApplicationReadyEvent.class) // <-- 모든 빈이 다 등록이 끝났을 때의 이벤트를 말함
public void run() {
bookService.printBookInfo("자바는 정석이다");
bookService.printBookInfo("자바는 정석이다");
bookService.printBookInfo("자바는 정석이다");
bookService.printBookInfo("자바는 정석이다");
}
}캐시를 사용하기 위해서 붙여줘야 하는 애노테이션입니다. Configuration 빈에 붙여도 되지만, 지금은 따로 캐시에 관련된 Config 설정을 한 것이 없기 때문에 MainApplication에 붙여줬습니다. 이제 다시 프로그램을 돌려보겠습니다.
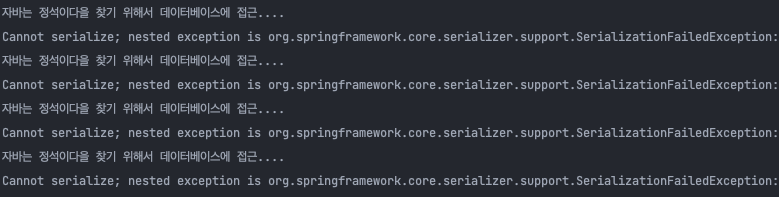
실행이 되긴 하는데, Serialize 할 수 없다고 뜹니다. 이건 Redis에 캐시 데이터를 저장할 때, 우리가 만든 Book 클래스를 Redis에서 기본설정되어 있는 Serialize 방법으로 직렬화하여 저장하게 됩니다. 이 말은 즉 캐시 데이터로 저장될 Book 클래스는 Serialize가 가능한 클래스가 되어야 한다는 것을 의미합니다. 코드를 수정해 보겠습니다.
# Book.java
@NoArgsConstructor
@AllArgsConstructor(staticName = "of")
@Data
public class Book implements Serializable {
private String title;
private String author;
private String publishedDate;
}Serializable 인터페이스를 implements 받아서 serialize가 가능한 클래스로 만들어줬습니다. 이제 다시 MainApplication을 재시작해봅시다.
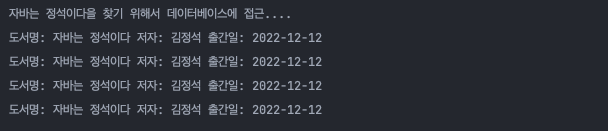
우리가 원하는 결과가 나왔습니다! 가장 처음에만 데이터베이스에 접근을 해서 데이터를 가져왔고, 그 뒤로는 데이터베이스가 아닌 캐시에 있는 데이터를 가져와서 출력했습니다.
이제 Redis Client로 가서 잘 등록되었는지 확인해 봅시다.

key가 잘 등록됐습니다. book이 key이고, (::)로 구분한 후 뒤에 나오는 부분이 "자바는 정석이다"라는 문자열을 인코딩하여 넣어둔 문자열 형태인 것 같습니다. 처음부터 영어로 잘 설정했으면 괜찮았을 거 같은데, 이 부분은 뒤쪽 리펙토링에서 한번 추가적으로 다뤄봅시다.
Redis를 사용해서 프로젝트에 캐시를 적용해 보는 작업은 끝났습니다. 하지만 몇 가지 더 코드를 리펙토링 해봅시다.
추가적인 리펙토링 작업
첫 번째로 캐시 데이터가 얼마나 저장되게 할 것인가를 설정해 봅시다. 이 부분은 성능과도 연관될 수 있는 부분이기 때문에 중요한 기능입니다. 캐시도 너무 많이 저장되고, 관리되지 않으면 서버에 부하가 걸립니다.
두 번째로 직렬화 방법을 바꿔볼 것입니다. 지금은 Redis의 Default 설정을 사용하고 있지만 우리에게 더 익숙한 JackSon 라이브러리를 사용하여 Serialize 방법을 바꿔봅시다. 그럼 더 보기 좋게 출력될 것입니다.
캐시 데이터 보관 기간 설정하기
Redis에 대한 설정을 커스텀하기 위해서는 @Configuration 애노테이션을 갖는 설정 클래스를 하나 생성해야 합니다.
# CustomRedisConfig.java
@EnableCaching
@Configuration
public class CustomRedisConfig {
@Bean
public RedisCacheConfiguration redisCacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(5)); // <-- 5초 뒤에 캐시 데이터가 삭제됩니다.
}
}MainApplication에 등록했었던 @EnableCaching 애노테이션을 가져옵니다. 이제 @Configuration이 존재하기 때문에 여기에 붙여주면 됩니다.
Redis 커스텀 설정을 위해서 RedisCacheConfiguration을 Bean으로 등록합니다. 우리가 설정하려는 TTL(Time To Live, 데이터 유효기간)을 5초로 설정한 후 return 하여 해당 인스턴스가 스프링 빈으로 등록될 수 있도록 합니다.
이제 다시 MainApplication을 실행시킨 다음에 5초 후에 "자바는 정석이다"가 사라지는지 확인해 봅시다. 그전에 해야 할 것이 있습니다. 아까 테스트할 때 등록되었던 캐시 데이터를 먼저 비워줘야 합니다.
>> flushall
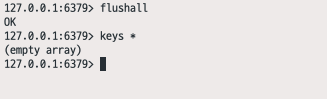
해당 명령어를 사용해서 모든 캐시 데이터를 삭제합니다. 그 후에 keys *로 삭제가 잘 되었는지 확인합니다. 그런 다음 MainApplciation을 한번 다시 돌려보겠습니다.

실행했을 때 처음에 keys *를 했을 때는 위처럼 데이터가 등록된 것을 볼 수 있고, 5초 후에 다시 keys *를 해보면 데이터가 사라진 것을 확인할 수 있습니다. 그래도 못 믿겠다면 Redis 서버에 찍힌 로그를 확인해 볼 수도 있습니다.
Serialize 방법 변경하기
이 부분도 Configuration에서 RedisCacheConfiguration의 설정을 변경해서 빈에 등록해 주면 됩니다. 앞서 사용했던 Bean에서 추가로 적용해 보겠습니다.
# CustomRedisConfig.java
import org.springframework.data.redis.serializer.RedisSerializationContext;
@EnableCaching
@Configuration
public class CustomRedisConfig {
@Bean
public RedisCacheConfiguration redisCacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(5))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
}
}이렇게 . 연산자가 많아지고, 가독성이 떨어질 때는 static import를 이용해서 아래와 같이 정리해 볼 수 있습니다.
import org.springframework.data.redis.serializer.RedisSerializationContext.SerializationPair;
@EnableCaching
@Configuration
public class CustomRedisConfig {
@Bean
public RedisCacheConfiguration redisCacheConfiguration() {
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(100))
.serializeValuesWith(SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
}
}이제 Redis의 Value 직렬화 방법을 Jackson2로 변경했습니다. 다시 MainApplication을 돌려봅시다. 캐시 TTL을 설정해서 Redis에 캐시 데이터가 남아있지 않지만 혹시 남아있는 분들은 꼭 다 삭제하고 재시작하시길 바랍니다.
Serialize가 적용된 것을 확인하기 위해서 TTL을 100초로 변경하고 해 보겠습니다. 5초면 등록되자마자 거의 바로 삭제되기 때문에 확인이 어렵습니다.

음... 직렬화가 되지 않았습니다. 여기서 문제점 한 가지가 있었습니다. 저희는 Configuration에서 직렬화 방법을 변경해 줬습니다. 그렇기 때문에 이전에 Book 클래스에 붙여줬던 Serializable 인터페이스의 implements는 지워줘야 합니다.
# Book.java
@NoArgsConstructor
@AllArgsConstructor(staticName = "of")
@Data
public class Book {
private String title;
private String author;
private String publishedDate;
}추가적으로 JackSon을 사용할 때는 @NoArgsConstructor를 사용해서 비어있는 생성자를 꼭 만들어두어야 정상적으로 작동됩니다.
이제 다시 MainApplication을 재시작해봅시다.

한글은 인코딩 되어 저렇게 뜨고 있지만 title, author, publishedDate에 대한 객체가 Jackson을 이용하여 JSON 형태로 Serialize 된 것을 볼 수 있습니다.
번외: Redis에서 한글 인코딩 방식 변경해 보기
Redis에서 한글을 보기 위해서는 다음과 같은 명령어로 Client를 실행하면 된다.
>> redis-cli --raw
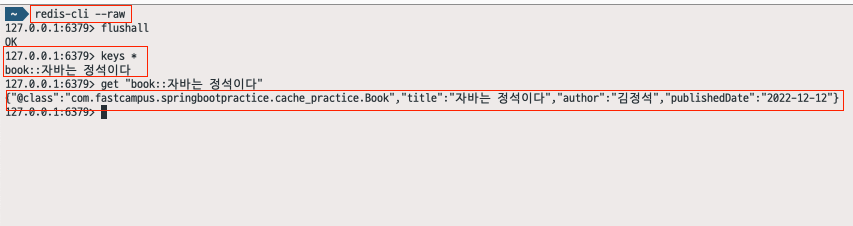
결과를 보면 "자바는 정석이다"라는 문자열이 잘 나오는 것을 볼 수 있다. JSON 타입으로 직렬화된 데이터도 잘 확인이 된다. Good ~
'🧑🏻💻 Dev > SpringBoot' 카테고리의 다른 글
| JackSon DTO 역직렬화 파헤치기 (JackSon과 Getter) (0) | 2023.09.25 |
|---|---|
| [Spring | LetsEncrypt] Http 서버를 Https로 바꿔보자 (0) | 2023.08.07 |
| [Spring] application.yml 설정값 가져오기 (0) | 2023.04.07 |
| [Spring] ExceptionHandler가 작동안 되는 오류 (컴포넌트 스캔) (0) | 2023.04.03 |
| [Spring/OAuth2.0] 스프링 페이스북 로그인 구현하기 (4) | 2023.03.16 |