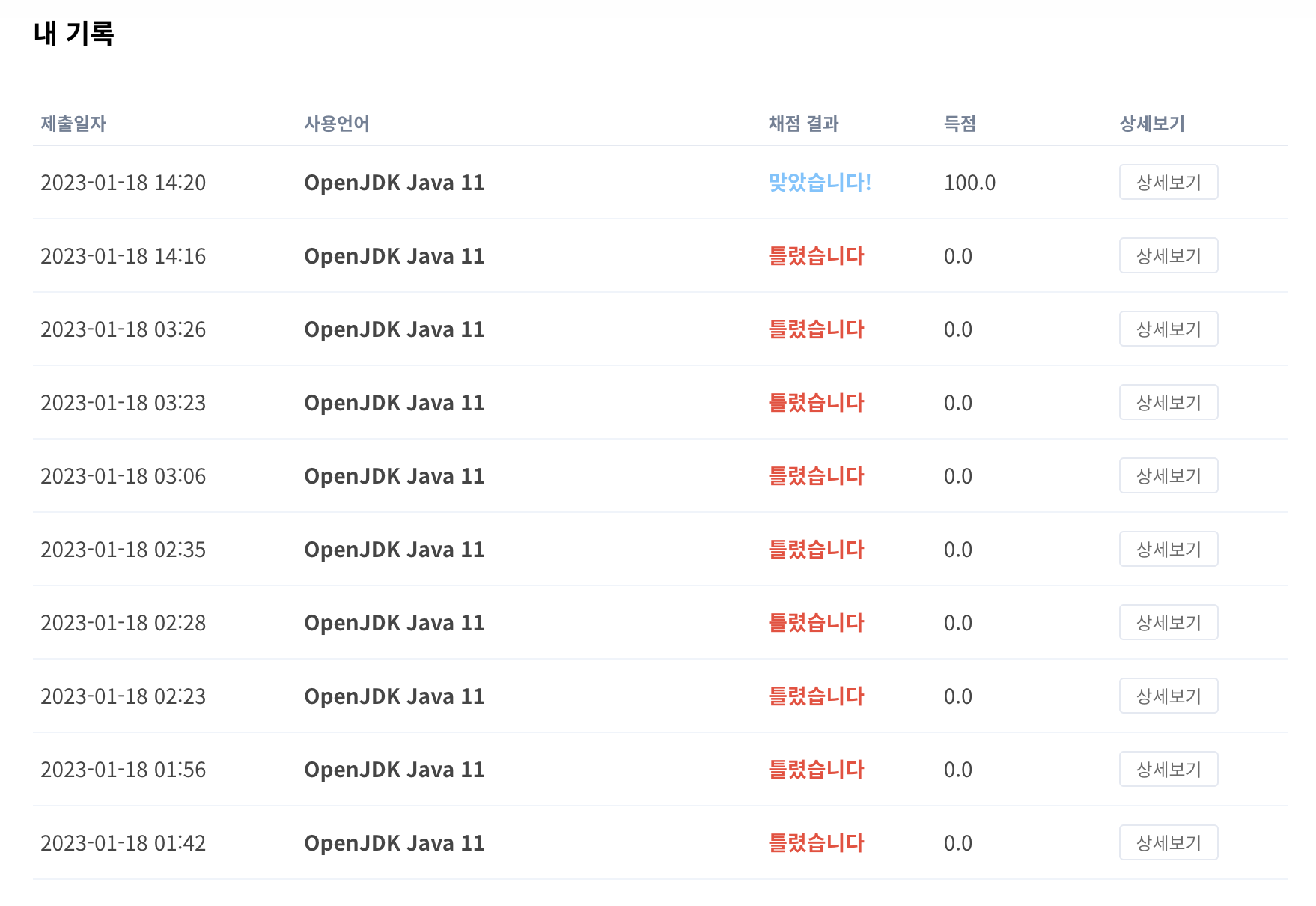
학교 수업에서 데이터를 입력받을 때, Scanner 객체를 만들어서 사용했었다. 근데 최근 알고리즘 문제를 풀다보니 많은 사람들이 BufferedReader 클래스를 사용하는 것을 발견했다. 둘의 차이점은 뭐가 있는지 알아보고자 한다.
사용하는 방법
Scanner 객체 만들기
Scanner scanner = new Scanner(System.in);생각보다 Scanner 객체를 만드는 것은 간단하다. System.in을 생성자 파라미터로 넣어서 생성해주면 된다. 이때 Scanner를 사용하기 위해서는 java.util를 import 해줘야 합니다.
BufferedReader 객체 만들기
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));BufferedReader 객체도 System.in을 파라미터로 받긴 하지만, 조금 다른 점이 있다. "InputStreamReader" 이 친구는 뭐하는 친구일까 한번 알아보자.
InputStreamReader란?
문자열을 읽을 때 Character 단위로 한 글자씩 읽어들이는 클래스라고 한다. InputStreamReader를 이용했을 때, 긴 문자열을 읽어들이는 것은 상당히 비효율적이기 때문에 BufferedReader가 생겼다고 한다.
여기서 BufferedReader의 특징이 하나 나타난다. Character 단위로 읽어들이던 InputStreamReader의 단점을 보완하기 위해서 "버퍼"를 이용한다.
한 글자씩 읽을 때는 사용자의 요청이 들어올 때마다 데이터를 읽어와야했었기 때문에 긴 문장이 들어오면 상당히 번거로웠다. 이때 BufferedReader를 사용하면 일정한 크기의 데이터를 한번에 읽어와서 "버퍼"에 보관을 합니다. 그리고 사용자의 요청이 들어오게 되었을 때, 버퍼에서 데이터를 읽어오는 방식을 사용합니다.
이런 특징으로 BufferedReader의 경우 InputStreamReader를 사용할 때보다 속도도 빠르고, 시간적인 부하도 적게 걸린다고 한다. 하지만 BufferedReader를 사용하면 입력을 Line 단위로 받기 때문에 공백(" ")의 경우도 String으로 받아들이게 됩니다.
BufferedReader로 입력받아서 사용하는 데이터는 String 타입의 데이터이기 때문에 만약 정수형이나 실수형 등 다른 데이터 타입으로 사용하고 싶다면 형 변환이 필요하다는 특징이 있습니다.
비교
그럼 Scanner와 BufferedReader에는 무슨 차이가 있을까. 앞서 설명했던 BufferedReader의 특징을 살펴보면, Line 단위로 데이터를 받아들이고, 입력된 데이터의 타입은 모두 String 타입이다. 그래서 항상 다양한 데이터로 활용하기 위해서는 형 변환이 필요하다.
반면, Scanner의 경우 공백, 줄바꿈을 모두 입력의 경계로 판단을 하기 때문에 좀 더 쉽게 데이터를 입력받을 수 있습니다. 또한 데이터를 입력받을 때, 데이터의 타입을 결정하기 때문에 별도의 형 변환이 필요 없다는 특징이 있습니다. 그럼 다 Scanner 쓰는게 좋은거 아닌가라는 생각이 들었다. 왜 Scanner를 놔두고 BufferedReader를 사용하는 걸까.

위에 있는 표를 보면 BufferedReader의 경우 8192로 Scanner보다 더 많은 버퍼의 크기를 가지고 있습니다. 그리고 단순히 문자열 자체를 읽어들이는 BufferedReader와 다르게 Sacnner는 문자열 파싱이 가능합니다. 그래서 상대적으로 속도는 BufferedReader가 더 빠릅니다.
또 다른 특징으로는 BufferedReader는 멀티 쓰레드 환경에서 동기화(Syncronized)가 되기 때문에 더 안전하다고 한다. 이 부분은 아직 겪어보지 않았기 때문에 생략을 하도록 하겠습니다.
그리고 BufferedReader를 사용하게되면 IOException에 대해서도 처리를 해줘야 합니다. 숫자 2개를 입력받아서 더한 값을 출력하는 메서드인 plus()를 한번 Scanner와 BufferedReader를 이용해서 구현해보겠습니다.
BufferedReader를 이용하여 구현
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class BufferedReaderEx {
public static void main(String[] args) throws IOException {
int result = plus();
System.out.println(result);
}
public static int plus() throws IOException {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));
int firstValue = Integer.parseInt(bufferedReader.readLine());
int secondValue = Integer.parseInt(bufferedReader.readLine());
bufferedReader.close();
return firstValue + secondValue;
}
}입력
1
3
출력
4
위에서 BufferedReader를 이용할 때의 특징을 확인해볼 수 있다.
- IOException을 던지기 때문에 메서드 차원에서 throws IOException을 처리해준 부분
- 이 부분은 try-catch로 잡아서 처리해도 무방합니다.
- 이 부분은 try-catch로 잡아서 처리해도 무방합니다.
- 입력된 데이터를 직접 파싱하여 정수형(int) 데이터로 사용하기
- Integer.parseInt()를 사용하여 문자열로 입력된 데이터인 "1"과 "3"을 정수형 데이터인 1과 3으로 변경하여 사용한다.
Scanner를 이용하여 구현
import java.util.Scanner;
public class ScannerEx {
public static void main(String[] args) {
int result = plus();
System.out.println(result);
}
public static int plus() {
Scanner scanner = new Scanner(System.in);
int firstValue = scanner.nextInt();
int secondValue = scanner.nextInt();
scanner.close();
return firstValue + secondValue;
}
}입력
1
3
출력
4
Scanner 객체를 이용하여 만든 코드가 더 간단해 보이는 것은 사실이다.
- IOException을 던지지 않기 때문에 예외를 처리해줄 필요가 없다.
- 문자열에 대한 파싱을 제공하기 때문에 scanner.nextInt()를 사용하면 별도의 파싱 작업을 해줄 필요가 없이 정수형 데이터로 사용할 수 있다.
어떤 것을 사용하는지는 본인의 선택이겠지만, 적은 데이터를 입력받을 때는 Scanner와 BufferedReader에서의 큰 차이를 못 느낄 것이다. 하지만 데이터의 양이 정말 많아진다면 문자열 파싱과 같은 복잡한 과정을 거치지 않고, 버퍼의 크기가 더 큰 BufferedReader의 속도가 빠르다는 것은 이제 알 것 같다.
Reference
https://carpediem0212.tistory.com/11
BufferedReader와 Scanner
이번 포스팅에서는 Java에서 문자열을 입력받는 목적으로 많이 사용되는 BufferedReader 클래스와 Scanner 클래스에 대해 알아보려합니다. 두 Class 모두 문자열을 입력 받는데 사용된다는 공통점이 있
carpediem0212.tistory.com
'🧑🏻💻 Dev > Java' 카테고리의 다른 글
| [Java] 열거형 (enum) (0) | 2023.02.08 |
|---|---|
| [Java] 문자열을 자르는 split()과 StringTokenizer (2) | 2023.02.03 |
| [디자인 패턴] 싱글톤 패턴 (0) | 2023.01.29 |
| [디자인 패턴] 템플릿 메서드 패턴 (0) | 2023.01.27 |
| [자바 자료구조] 스택(Stack)과 큐(Queue) (0) | 2023.01.17 |